Chapter 4 Life’s secrets to make complex organic molecules
Chapter summary:
- Living organisms have a seemingly infinite complexity and diversity of molecules
- Yet, most organisms are made of 6 major atoms CHONSP assembled into four major molecular families: carbohydrates, proteins, lipids, and nucleic acids
- Complex molecules generally are polymers of simple monomers
- Each molecular family has specific structure to achieve specific function. Details of each are summarized in this chapter
- These four family constitute what we refer to as primary metabolites and are considered ubiquitous to all plants for growth and development
- Plants metabolize secondary metabolites, most of which are referred to as phenolics for defense against other organisms, as signaling compounds, and for protection against ultraviolet radiation and oxidants
- Phenolics play a disproportionate role in regulating microbially mediated processes in ecologically engineered treatment systems
- In organic molecules, about 4 electrons are stored on each carbon atom, none on the phosphorus, and always 8 electrons on the nitrogen and sulfur atoms
4.1 Polymers of simple monomers
When scientists of the 18th century observed nature, they thought there had to be major differences between animated organisms and the inanimate ones. In fact they thought that the elements at the basis of the animated vs. inanimate things had to be different. One can only wonder at the incredible diversity and complexity of forms between a bacterium and humans, and between unicellular algae and sequoia trees! And yet, despite the incredible variations of life forms and sizes, there is a common theme: very complex organic molecules correspond to the assemblage of simple molecules and in many cases are polymers of relatively simple monomers.
In the image of a brick wall and the skyscraper in Figure 4.1, it is possible to make a small wall or a huge skyscraper. Brick walls are made of bricks and of mortar to hold the bricks together. If one adds metal pieces, wood, etc. the complexity of the final product can be infinite, yet it is made from simple elementary pieces.


Figure 4.1: Small and large structures can be built from the addition of bricks, one at a time
Living organisms are essentially made of very complex polymers, but which are in most cases built from simple monomers. Just like in a building which complexity results from the assemblage of different types of material, e.g., bricks, wood, metal, etc., living organisms are assembled from distinct ‘types of molecules’. Among the very complex organic polymers, one can distinguish four molecular families. Molecular families can be identified because
- within a family, there are polymers of similar monomers
- the monomers are distinct between families
- and there tends to be unique chemical bonds between consecutive monomers allowing polyremisation.
The vast majority of the organic matter that makes cells and organisms have been classified into four molecular families:
- Carbohydrates
- Proteins
- Nucleic acids
- Lipids
The monomers of these four families are sometimes referred to as primary metabolites in the sense that they are ubiquitous in the plant and animal world and constitute the elementary bricks for most of the functions and structures of living creatures from bacteria to humans. This chapter will present in details the monomers and polymers for each of the family.
As I was writing this book, it became obvious that I could not ignore another important group of molecules which play a disproportionate role in ecological engineering: the phenolics. Phenolics are referred to as secondary metabolites “not directly essential for basic photosynthetic or respiratory metabolism but are thought to be required for plants’ survival in the environment. […] Secondary metabolites apparently act as defense (against herbivores, microbes, viruses, or competing plants) and signal com-pounds (to attract pollinating or seed dispersing animals), as well as protecting the plant from ultraviolet radiation and oxidants.” (Lattanzio 2013). We will explore the mystery behind these fascinating molecules.
Before we get into the details of each family and of phenolics, Table 4.1 below summarizes some of the major attributes of each of the molecular family. Although the CHONSP elements constitute organic matter in general, no one family is constituted of all these six atoms! Carbohydrates and lipids are mostly made of CHO, with additional N and P for lipids. Proteins are the only molecules where S is present. Carbohydrates and lipids play a major role in energy storage and cellular structure, while nucleic acids only store and transcribe the genetic information, and this information is transcribed into very precise sequence of amino acids forming proteins and giving them their functions.
| Carbohydrates | Proteins | Nucleic Acids | Lipids | |
|---|---|---|---|---|
| General formula | CnH2nOn | CHONS | CHONP | CHO(N)P |
| Monomers | monosaccharides, hexoses | amino acids | nucleotides | fatty acids + backbone + polar head |
| Number of electrons stored | ~4 on C | ~4 on C, 8 on N and S | ~4 on C, 8 on N, 0 on P | ~6 on C, 8 on N, 0 on P |
| Cement | glycosidic bond | peptidic bond | phosphodiester bond | ester, ether, and phosphoester bond |
| Functions | Storage and transport of energy, cell and organism structure | reaction catalysis, exchange, regulation, information transfer | genetic code storage and transcription | cell structure and energy storage |
| Examples | sucrose, cellulose, starch, chitin, glycogen | enzymes, keratin, muscles, hemoglobin | RNAs and DNA | fatty acids, oils, cholesterol |
Understanding and knowing enough of the atomic and molecular makeshift of organic matter in general and of each molecular family in particular, belongs in our opinion, to the minimum ‘alphabet’ needed to better understand biogeochemical processes as organic matter is the fuel for all these processes.
4.2 Carbohydrates
Carbohydrates form the entry molecules onto which electrons are first stored in photosynthesis, and precisely on the carbon atoms. The generic formula for carbohydrates is (CH2O)n, and each atom, on average, has 4 electrons for itself as illustrated in Figure 4.2. We have seen in the previous chapter that having 4 electrons stored on each C is probably the most cost effective way to store many electrons on organic molecules.
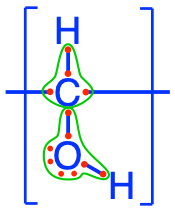
Figure 4.2: Electron allocation of a generic carbohydrate (CH2O)n
Carbohydrates are a rather homogeneous group as they include clearly identified monomers and polymers of these monomers. Most monomers are C6 or C5 rings and can, depending on their nature and on their polymerization type, serve very different purposes including energy storage (e.g., starch), structure (e.g., cellulose or chitin of cructacean shells), or as backbone of RNA (e.g., ribose). On an everyday life basis, carbohydrates are present in paper, sugar, pasta, grain, etc. (some common carbohydrates in food illustrated in Figure 4.3).

Figure 4.3: Assortment of everyday food containing carbohydrates. Obtained from https://www.measureup.com.au/all-about-carbohydrates/
4.2.1 Monosaccharides
The monomers of carbohydrates are called monosaccharides (from Greek monos, i.e., single, and sacchar, sugar) or called simple sugars or oses (from the Latin “full of, abounding in, having qualities of”). The monomers that are assembled into complex polymers generally are hexoses, that is that they have 6 carbons, and are isomers of glucose. However, monosaccharides do include more than just hexoses or C6H12O6, and it is important to present them in general, and not just the monomers of polysaccharides.
Most monosaccharides are made of 3 to 6 carbons (there actually are C7 to C9 oses) and are classified in aldoses or ketoses, depending on whether they have a aldehyde (-CHO) on their C#1 or a ketone (-C=O) radical, usually on the carbon numbered #2 (details on these functional groups in sections 3.2.9 and 3.2.10). They either exist in linear chains and are then represented in Fischer projection like in Figures 4.4 and 4.5, or, for pentoses (C5) and hexoses (C6), exist in cyclic chains (Figures 4.12 and 4.11). Carbohydrates have been given a lot of codes and naming conventions and it is hard to avoid them if we want to put things together. So, there is no reason to fear all the names and letters used to describe and differentiate carbohydrates. The goal is:
- to realize the large diversity of monosaccharides
- to realize that the differences between, e.g., the hexoses are of steric consideration, i.e., which side are the hydroxy (-OH) groups of the linear chain, right or left.
- to realize that C5 and C6 carbohydrates alternate between chain and cyclic molecular configurations. The cyclic form prevails for the functions of transport and structure that the carbohydrates provide. The chain form is the form needed for the release of electrons and energy. Both forms interchange freely for monosaccharides.
](pictures/aldoses-nb.png)
Figure 4.4: classification of C3 to C6 aldoses in Fischer projection. Triose : (1) D-(+)-glyceraldehyde ; Tetroses : (2a) D-(−)-erythrose ; (2b) D-(−)-threose ; Pentoses : (3a) D-(−)-ribose ; (3b) D-(−)-arabinose ; (3c) D-(+)-xylose ; (3d) D-(−)-lyxose ; Hexoses : (4a) D-(+)-allose ; (4b) D-(+)-altrose ; (4c) D-(+)-glucose ; (4d) D-(+)-mannose ; (4e) D-(−)-gulose ; (4f) D-(−)-idose ; (4g) D-(+)-galactose ; (4h) D-(+)-talose. after Yikrazuul — personal work, public Domain
Time to incorporate some jargon. When in the chain form necessary for the carbons to donate their electrons, monosaccharides are called reducing sugars. This means that they are able to donate their electrons, to drive respiration and the generation of energy in the cell (details in Chapter 5). So, despite the fact that each carbon atom on monosaccharides has on average 4 electrons to give, potentially, this does not systematically happen. This is rather unexpected. Indeed, for the pentoses and hexoses to be reducing sugars, they must be in the aldose form, or have a free aldehyde at the end of their chain or on carbon #1. Does this rules out the ketoses? Actually no, the ketoses in the chain form can be readily tautomerized into aldoses. This is only important to explain some of the differences in disaccharides.
](pictures/ketoses-nb.png)
Figure 4.5: classification of C3 to C6 ketoses in Fischer projection. Triose : (1) dihydroxyacetone ; Tetrose : (2) D-erythrulose ; Pentoses : (3a) D-ribulose ; (3b) D-xylulose ; Hexoses : (4a) D-psicose ; (4b) D-fructose ; (4c) D-sorbose ; (4d) D-tagatose. after Yikrazuul — personal work, public Domain
You might wonder what the D-(+) or D-(-) might mean in the legends of Figures 4.4 and 4.5… This is due to optical rotation properties that a pure solution of a particular ose has because of the asymmetry of the molecules. The different forms of hexoses in, e.g., Figure 4.4 are called eniantiomers. D means that the hydroxy group on the C#n-1 to the right of the molecule and most natural oses tend to be D (few oses have it on the left, in which case they are coded as L). The (+) or (-) tell whether the light rotation is pulled towards positive or negative angles. OK, lots of terms here, mostly to quench some of the curiosity of the biochemist in you.
The first lesson from this litany of hexoses calls for a bit of putting things together. Carbohydrates in general are the entry point for life to store high energy electrons onto carbon, via photosynthesis. All hexoses presented above, and in fact all monosaccharides, have on average 4 electrons stored on the carbon atoms. This is the most efficient way to store electrons because it consists in storing the number equivalent of the number of valence electrons on carbon in its natural state, that is 4 electrons. So carbohydrates do have, on average, 4 electrons per carbon atom. It turns out that alcohol functional groups allow the storage of 4 electons per carbon atom in a carbon chain. Carbohydrates must thus have chains of alcohol groups. However, because carbohydrates are the entry point to store energy, the elementary molecules synthesized have to be relatively small not to add weight onto leaves where they are produced and such that they can be easily transported away from the leaves into storage areas. The elementary molecules in carbohydrates are C3, C5 and C6 molecules, which fulfills the need for small molecules.
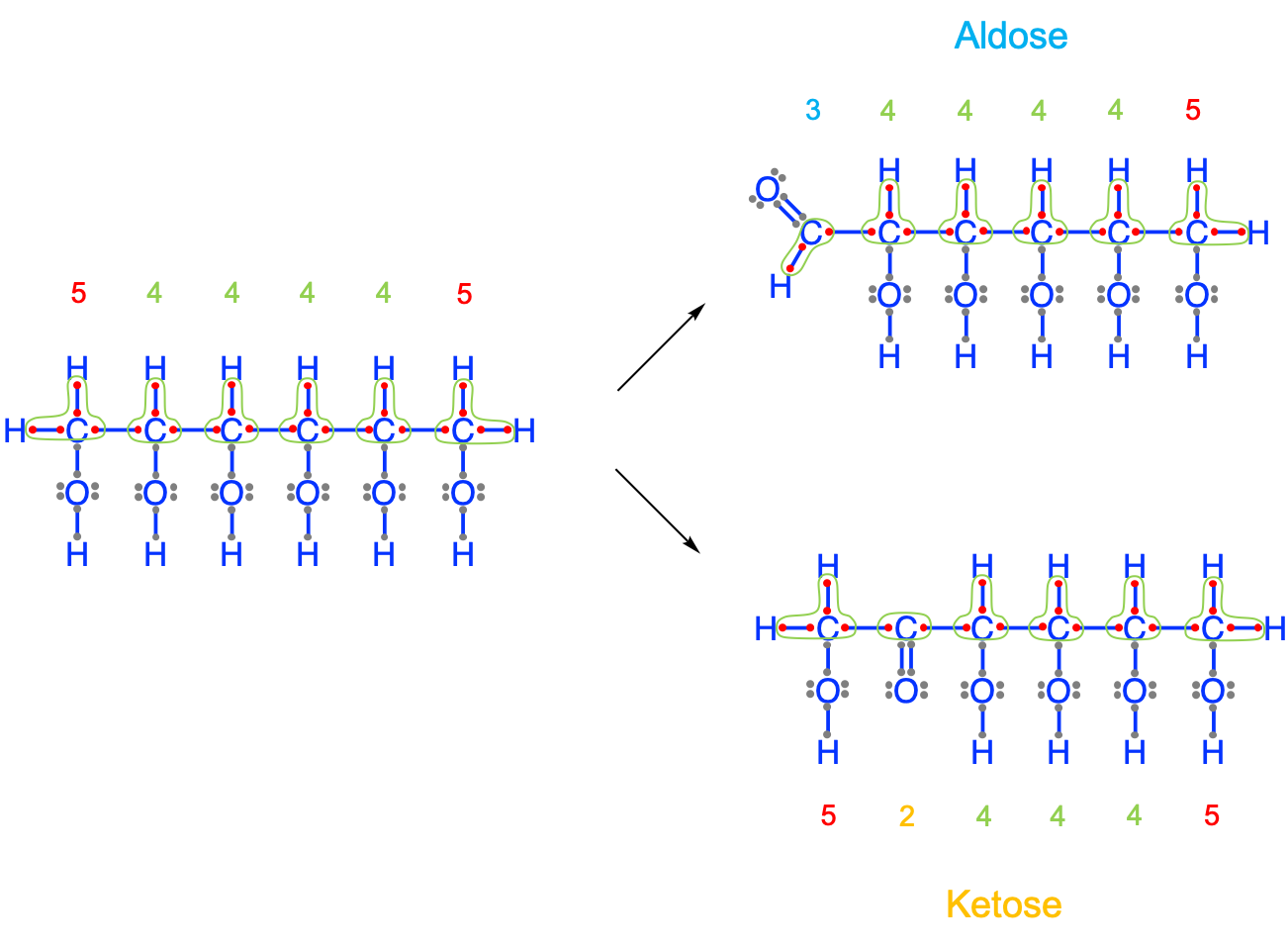
Figure 4.6: Natural formation of aldoses and ketoses from a hypothetical hexan-hex-ol to keep 4 electrons per atom on average for a C6 carbohydrate. The electrons have been allocated on the carbon atoms (green line) according to the electronegativity rule. The electrons on the oxygen atoms have been ignored because they do not participate in the storage of electrons
The result of this demonstration is that on a C6 hexose molecule, there should be 24 electrons stored. Using a chain of 6 alcohol groups yields a hexan-hex-ol, where the end carbons have 5 electrons for themselves, hence a total of 26 electrons, or 2 more than expected (Figure 4.6). The ‘solution’ nature has found is to replace one of the end alcohol groups with either an aldehyde group at the end, or another alcohol group with a ketone group. The first case leads to aldoses and the second to ketoses described above. It it thus no accident that monosaccharides have aldehyde and ketone functional groups.
For the anecdote, hexan-hex-ol isomers represented on the left of Figure 4.6 do exist in nature in small amounts and are now synthesized in the industry as thickeners and low calories sweeteners because they are poorly absorbed by the intestines. They are referred to as sugar alcohols as the suffix -itol indicates. Some names might be familiar and include xylitol, sorbitol, and mannitol. Putting C6 hex-ols into a cycle leads to inositol or cyclohexane-1,2,3,4,5,6-hexol, which is an essential compound in the brain. All of the sugar alcohols are synthesized from glucose by plants and animals.
Actually, in inositol, each carbon does have 4 electrons for itself, so nature could have kept it to store energy. However, the C-C covalent bonds are difficult to break, and nature has not kept this option. Rather, it went for glucose, the solution that could quickly store and release energy, and provide structural strength. And all that in one molecule!
Now that we have a more holistic view of what monosaccharides are made of, for all our purposes, we will reduce all this great variability to a few of them, which are glyceraldehyde (C3), ribose and deoxyribose (C5), and, glucose and fructose (C6).
Glyceraldehyde is an important intermediate molecule of photosynthesis and is an example of the demonstration above for a C3 carbohydrate (Figure 4.7). We have seen the glycerol molecule in section 3.4, which is a propan-tri-ol, or three hydroxy group on each of the 3 carbons, which ends up as a moiety for lipids. Glyceraldehyde apparently looks like a glycerol of which an end alcohol group would be oxidized to an aldehyde group. This is technically true but it is better to view the aldehyde group as a necessity to keep 4 electrons per carbon atom.
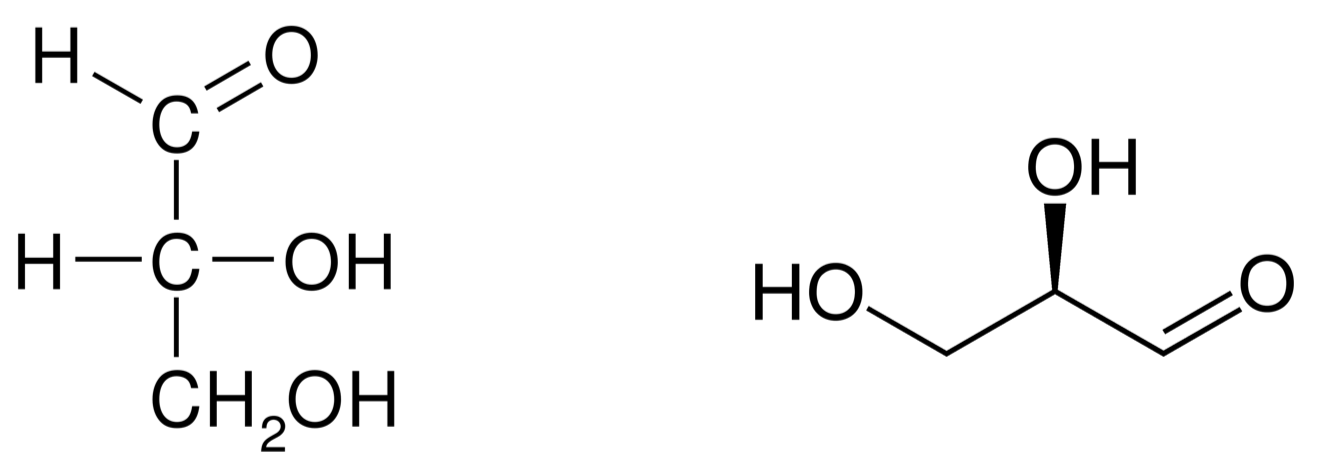
Figure 4.7: Fisher projection (left) and skeletal formula (right) of D-glyceraldehyde
Hexose and pentose monosaccharides have two main roles: an energy release role when they are in their linear form, and a structural role when they are in their cyclic configuration as they serve as structural moeities (pentoses) and as the elementary monomers for the construction of disaccharides or more complex carbohydrates (hexoses). This might, admitedly, sound a little odd, as one might have the idea that a molecule is a rather stable physical entity. In their linear form, they can be incorporated into the metabolic pathway of cells where the electrons stored on the carbons can be released. A ‘sugar’ (i.e., the generic term also used to describe carbohydrates) that has the ability to act as a reducing agent because it has a free aldehyde group or a free ketone group, is referred to as a reducing sugar. Thanks to their ability to freely switch from a linear to a cycling form, C5 and C6 monosaccharides are reducing sugars.
Pentoses and hexoses have the tendency to form cyclic or ring molecules “through a nucleophilic addition reaction between the carbonyl group and one of the hydroxys of the same molecule. The reaction creates a ring of carbon atoms closed by one bridging oxygen atom” (Wikipedia contributors 2018e). This property, again, is the result of the necessity to have either an aldehyde or a ketone group in the C6 chain to keep the average of 4 electrons per carbon atom. The most common rings are made of 5 or 6 atoms, respectively, with four C atoms and one O atom, and, five C atoms and one O atom (cyclic forms also referred to as furanose - Figure 4.8 - and pyranose - Figure 4.9 - , respectively, because they closely resemble furan, and pyran rings).
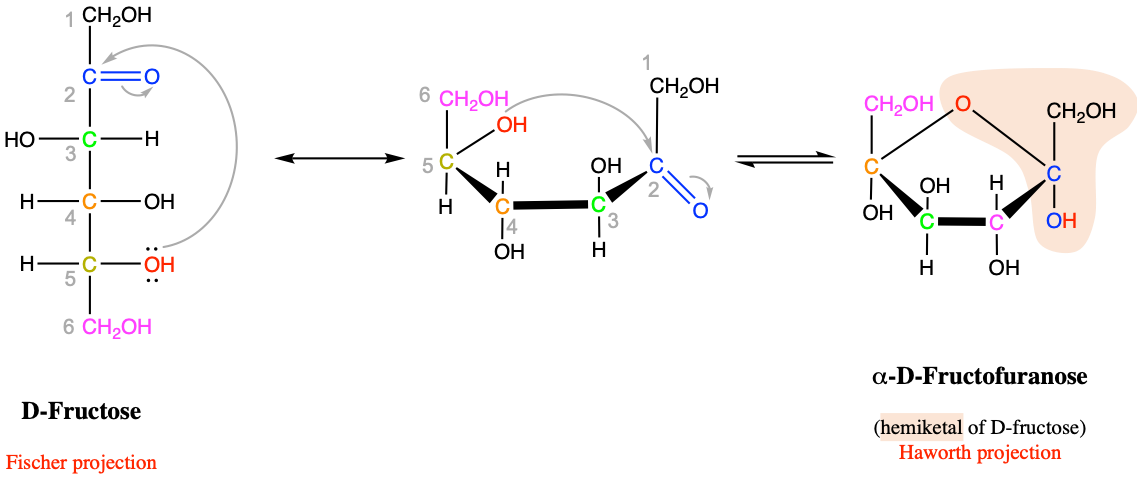
Figure 4.8: Intramolecular cyclic hemiketal formation in fructose and more generally for furanose hexoses
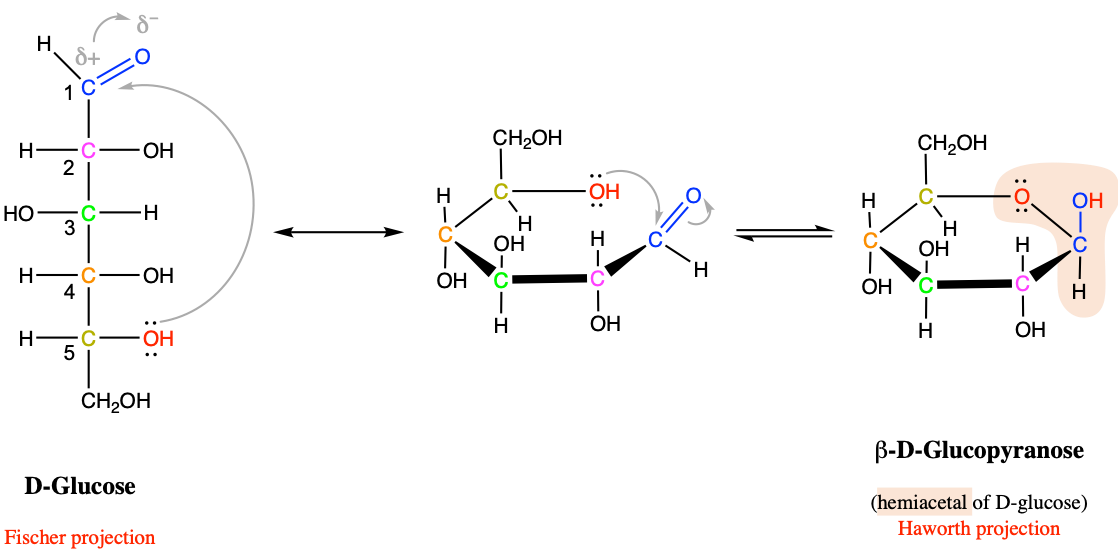
Figure 4.9: Intramolecular cyclic hemiacetal formation in glucose and more generally for pyranose hexoses
Now, as the pentoses and hexoses form rings, the acetal functional group is formed (as previously detailed in section 3.3.6). For the aldohexoses to form rings, the aldehyde on carbon #1 (Figures 4.9) reacts with the hydroxy of carbon #5 to form a 6 atom ring. And in can easily revert to the chain structure to have a free aldehyde again and be a reducing sugar. For fructose, a ketohexose, the ketone from carbon #2, reacts with the hydroxy of also carbon #5, to now form a 5 atom ring (Figure 4.8). So why is this important enough to be mentioned here…?
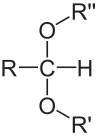
Figure 4.10: Structure of a generic acetal By NEUROtiker - Own work, Public Domain, https://commons.wikimedia.org/w/index.php?curid=3508032
In the ring versions of the glucose and fructose, the carbons #1 and #2 now have single bonds with two oxygen atoms. This acetal group formed by a central carbon, and bonded in a tetrahedral as illustrated in Figure 4.10 is a rather special bond. In fact, special enough that it has some interesting consequences, with two different forms. If one of the atoms bonded to oxygen is different than hydrogen (e.g., R’ and R” in Figure 4.10 both not H), then this group is called an acetal group, and the bond is a rather stable bond. If one of the R’ or R” in Figure 4.10 is H, while the other has some other radical, then the structure becomes asymmetric, the group formed is then called hemiacetal as is not nearly as stable. This explains why the hexoses may so easily switch from the linear chain to the cyclic configurations. These hemiacetal and hemiketal groups are one of the basis of the glycosidic bond, which binds the cyclic pentoses and hexoses in di- and polysaccharides, but also with other molecules.
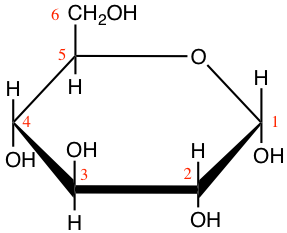

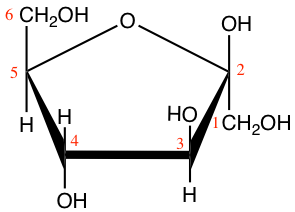
Figure 4.11: Cyclic structure or Haworth projection of alpha-D-glucopyranose (alpha-D-glucose; left) and beta-D-fructofuranose (beta-D-fructose; right)
In Figure 4.11, both glucose and fructose are hexoses. But fructose generally forms furanose rings (5 atoms, including one oxygen atom), while glucose forms pyranose rings. The α and β correspond to whether the hydroxy on the C#1 atom is below (α) or above (β) the plan made by the ring. Some more jargon here added for exactness of information only.
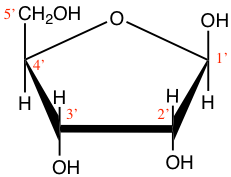
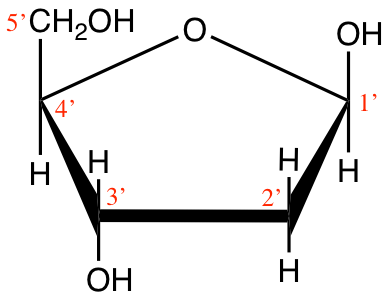
Figure 4.12: Cyclic structure of beta-D-Ribofuranose (beta-D-ribose) and 2-deoxyribose
Ribose and deoxyribose are the most important pentoses we need to know as they constitute one of the three ensembles or moeities that constitute nucleotides, i.e., the monomers of nucleic acids. They both exist either in furanose or pyranose forms, although the furanose form dominates, but the difference between ribose and deoxyribose is the missing oxygen atom on the 2’ carbon atom (Figure 4.12). And indeed, this difference is the reason for the ‘R’ and ‘D’ in the RNA and DNA molecules. Notice that the carbon atoms are numbered in Figures 4.11 and 4.12. The numbers are ‘primed’ for the ribose and deoxyribose (Figure 4.12). This is a convention that geneticists have used to differentiate the carbons from the pentose to those of the base in nucleotides (see part on nucleic acids). This is anecdotal information again.
Exercise 4.1 Draw some basic monosaccharides
In the JSME editor below, draw the molecules listed underneath. You may also render them in 3D in JSmol by going directly to JSmol demo page and click on the “JSME embedded with JSmol, for 2D⇄3D conversion” link.
Draw a ribose (C5) in its aldose form
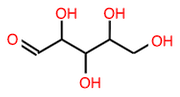 (Ans: O=CC(O)C(O)C(O)CO))
(Ans: O=CC(O)C(O)C(O)CO))Draw the furanose form of ribose (Ans: OCC1OC(O)C(O)C1O)
Draw a aldose form of an hexose (Ans: O=CC(O)C(O)C(O)C(O)CO)
Draw a ketose form of an hexose (Ans: O=C(CO)C(O)C(O)C(O)CO)
Draw a furanose form of an hexose, e.g. fructose (Ans: OCC1OC(O)(CO)C(O)C1O)
Draw a pyranose form of an hexose, e.g. glucose (Ans: OCC1OC(O)C(O)C(O)C1O)
In summary:
Monosaccharides
- The most efficient way to capture and store energy nature has found is to store 4 electrons per carbon atom directly from photosynthesis, and the carbohydrates are the macromolecules where this storage first occurs
- Alcohol functional groups allow the storage of 4 electrons per carbon atom in a carbon chain and monosaccharides’ formula can generally be written as (CH2O)n where 3 < n < 6 generally
- To keep the relatively small C3, C5 and C6 molecules with an average of 4 electrons per carbon atom, one of the alcohol groups has to lose electrons hence the presence of aldehyde and ketone functional groups
- It is thanks to the presence, and the steric configuration, of the aldehyde and the ketone groups that C5 and C6 molecules readily alternate between linear and ring forms, the latter existing thanks to hemiketal and hemiacetal functional groups
- It is thanks to the rather unstable nature of the hemiketal and hemiacetal functional groups that the monosaccharides can easily switch configurations from linear chains where they can fulfill their role as electron donors, and cyclic rings where they act as structural monomers of di- and polysaccharides for the hexoses or as structural moieties for pentoses
- Thanks to all the hydroxy groups, monosaccharides are extremely soluble in water
- Small differences in the position of the hydroxys, and in the cyclization of the C5 and C6 make for different monosaccharides
- The C3 atom monosaccharide to remember is glyceraldehyde
- Glucose is arguably the most important monosaccharide and the only hexose molecule expected to be known by heart
For glucose, and for organic chemistry in general, there are several ways of representing molecules. One of the ways is the Haworth projection as shown in Figures 4.11 and 4.12. Another way is called the Fischer projection as illustrated in Figures 4.4 and 4.5. Another way is called the skeletal formula where the carbons are implied at the corners and the ends of line segments, while oxygen and other remarkable radicals such as hydroxy or amine are noted. Glucose is thus often represented as skeletal formula as in the left of Figure 4.13. Another even more simplified representation of glucose is represented in the ‘hyper’ skeletal formula. The latter has the advantage to be simple enough and used to illustrate polysaccharides.
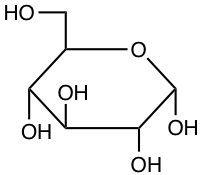
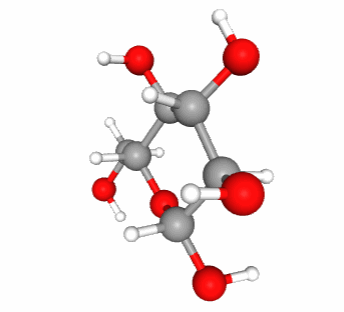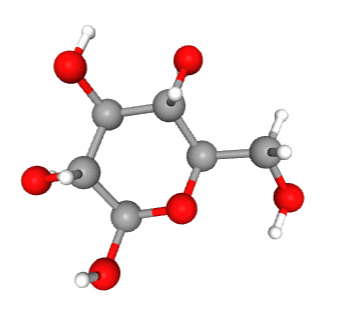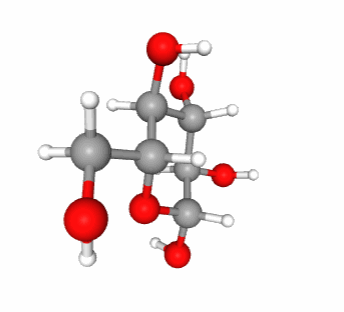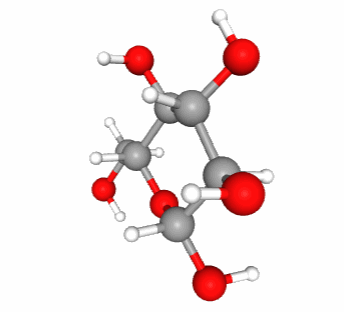
Figure 4.13: Skeletal formula for alpha-D-glucose (left), ‘hyper’ skeletal formula (center), and 3-D representation with C in grey, O in red, and H in white. Notice that in 3-D, the pyranose ring is not flat. It would if it were an aromatic ring
In reality, there is an entire field of chemical research that deals with the representation of molecules, often in 3D, using computer graphics. A scalable 3-D representation of alpha-D glucose can be directly visualized at this location for example.
4.2.2 Dissacharides
Sucrose, lactose, and maltose are three common dissaccharides. Dissacharides are bioses or polymers of two hexose monomers. Because they are still small, and thanks to their solubility in water (thanks to hydroxy groups), they play an essential role to transport energy in chemical forms because for a slight increase of the osmotic pressure in a liquid, dissaccharides carry twice the number of electrons.
Dissaccharides correspond to the assemblage of two monosaccharides thanks to the glycosidic bond. The name of this bond suggests that it is very specific to carbohydrates, and it is true as one monosaccharide must be involved in a glycosidic bond. So the glycosidic bond is a type of covalent bond that joins a carbohydrate (sugar) molecule to another group, which may or may not be another carbohydrate. The common theme, however, is that the carbon of the sugar involved corresponds to that of the hemiacetal group. There are 4 types of glycosidic bonds, depending on the atom directly linked to the hemiacetal carbon of the carbohydrate: O-, N-, S-, or C-glycosidic bonds. Figure 4.14 illustrates the generic O- and N-glycosidic bond.
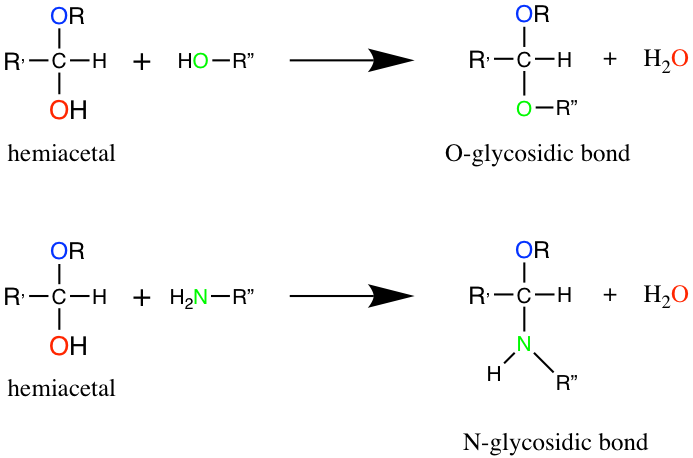
Figure 4.14: Formation of glycosidic bonds between a hemiacetal Carbon and a hydroxy or amine group, to respectively form O- and N-glycosidic bonds.
The N-glycosidic bond occurs in nucleotides and thus plays a major role. But overall, the term glycosidic bond generally refers to the O-glycosidic bond between two consecutive monosaccharides (Figure 4.15). In the end, and to go back to the brick and mortar analogy, for di- and polysaccharides, the glycosidic bond is the equivalent of the mortar.
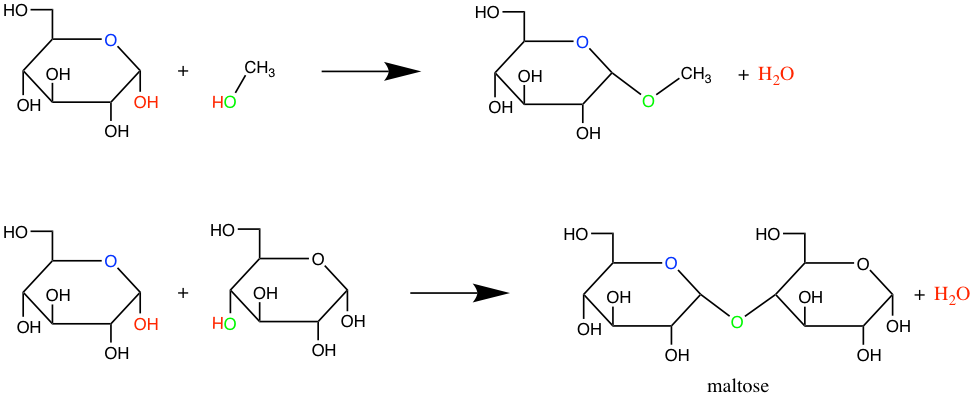
Figure 4.15: Formation of glycosidic bonds between a glucose hemiacetal carbon and a methyl hydroxyde (top) or between two glucoses to form maltose
Lactose and maltose (Figure 4.16) are dissaccharides, respectively assembled from a galactose and a glucose, and, from two glucose molecules. Notice that these two molecules are reducing sugars, i.e., there is one hemicetal carbon (C#1) free to potentially open one glucose into a chain form, hence the ability for both lactose and maltose to be readily available as electron donors. This is quite nice for lactose produced by mammal females to be readily available for their offsprings. On another note, during seed germination, starch (details below) is hydrolyzed into maltose first by the amylase enzyme, and then readily participate in energy generation for this critical time of seed plant lives.

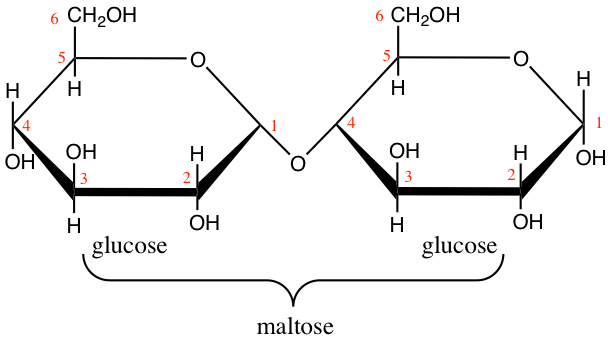
Figure 4.16: Lactose and maltose dissaccharides molecular formulae
Interestingly, sucrose in not a reducing sugar as both hemiacetal carbons (C#1 of glucose, and C#2 of fructose) are part of the glycosidic bond (Figure 4.17). There are several advantages:
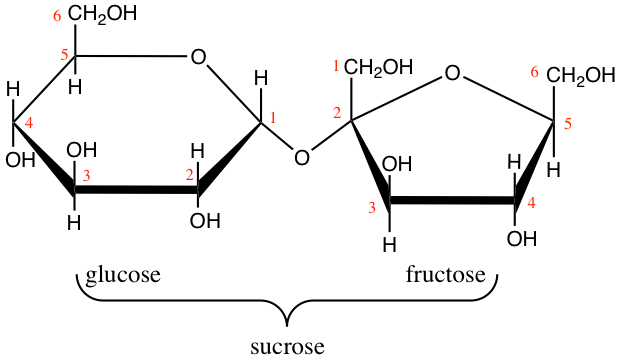
Figure 4.17: Sucrose molecular formula
- Sucrose is a very stable molecule, and a lot more than lactose and maltose. Hydrolysis of the glycosidic bond is very slow and solutions of sucrose can last for a very long time.
- Because both hemiacetal carbons are bonded, there are no more possibilities for an additional glycosidic bond to take place: sucrose stays as a dissaccharide
This is actually essential for green vascular plants, which assemble sucrose in their leaves from glucose and fructose, but must transport these molecules away from the leaves to minimize weight and avoid jamming of the photosynthesis. So having a very stable, highly soluble, not polymerisable, non reducing molecule is very advantageous. Sucrose can then be hydrolyzed thanks to the sucrase enzyme into glucose and fructose again for use or storage at other places in the plants.
Exercise 4.2 Draw some basic dissaccharides
In the JSME editor below, draw the molecules listed underneath. You may also render them in 3D in JSmol by going directly to JSmol demo page and click on the “JSME embedded with JSmol, for 2D⇄3D conversion” link.
Draw a molecule of sucrose: non-reducing sugar involving glucose-fructose (hexofuranose) with a 1 - 1 link (Ans: OCC2OC(OC1(CO)OC(CO)C(O)C1O)C(O)C(O)C2O)
Draw a molecule of maltose: reducing sugar involving glucose-glucose with a 1 - 4 link (Ans:
OC[C@H]2O[C@H](O[C@H]1[C@H](O)[C@@H](O)C(O)O[C@@H]1CO)[C@H](O)[C@@H](O)[C@@H]2O(isomeric SMILES) or- OCC2OC(OC1C(O)C(O)C(O)OC1CO)C(O)C(O)C2O) (canonical SMILES)
Draw a molecule of lactose: reducing sugar involving galactose-glucose with a 1 - 4 link (Ans:
C([C@@H]1[C@@H]([C@@H]([C@H]([C@@H](O1)O[C@@H]2[C@H](O[C@H]([C@@H]([C@H]2O)O)O)CO)O)O)O)O(isomeric SMILES) or- OCC2OC(OC1C(O)C(O)C(O)OC1CO)C(O)C(O)C2O) (canonical SMILES)
Notice that the difference between lactose and maltose is only isomeric, the formula is exactly the same.
In summary:
Disaccharides
- The glycosidic bond always involves one hemiacetal group and is the key for the formation of carbohydrate dimers, and also polymers
- Dissacharides are small molecules which are easily soluble thanks to the many hydroxy groups and easily transportable
- For a very similar osmotic pressure, dissaccharides carry twice as many electrons as monosaccharides: dissaccharides are the ‘go to’ transport molecules
- Sucrose, a very stable molecule, non reducing sugar, is the molecule used by vascular plants to transport the products of photosynthesis (glucose and fructose) from the leaves to storage areas (both sometimes located very far apart - think about sequoias!)
4.2.3 Polyssaccharides or glycans
Polysaccharides are polymers of monosaccharides linked together thanks to the glycosidic bond, forming sometimes very long chains (at least more than 10 monosaccharides, or else are referred to oligosaccharides), either linear or branched. The polysaccharide chains are also referred to as glycans, the suffix an implying a chain of monosaccharides. In glycan, the prefix glyc refers to the generic carbohydrate. The term glucan refers to a chain of glucose monomers, similarly, the term xylan, refers to a chain of xylose monomers, and so on.
Polysaccharides generally have two main functions: energy storage or structure. Because of the glycosidic bond, which removes a molecule of H2O, the general formula for a large polysaccharide is more like (C6H10O5)n often with 200 < n < 3500. For our purpose, it is important to remember that there are three main polysaccharides: homopolysaccharides or homoglycans, i.e., long chains of the same monomers (homo: same), and heteropolysaccharides or heteroglycans, long chains of a variety of monomers (hetero: different), generally separated into hemicelluloses and pectins.
4.2.3.1 Homopolysaccharides or homoglycans
Among the most important homopolysaccharides, one can distinguish starch and glycogen, which are both energy storage molecules for plants, and animals, respectively, and, cellulose which has a structure function making a lot of the plants cell walls (Figure 4.18).
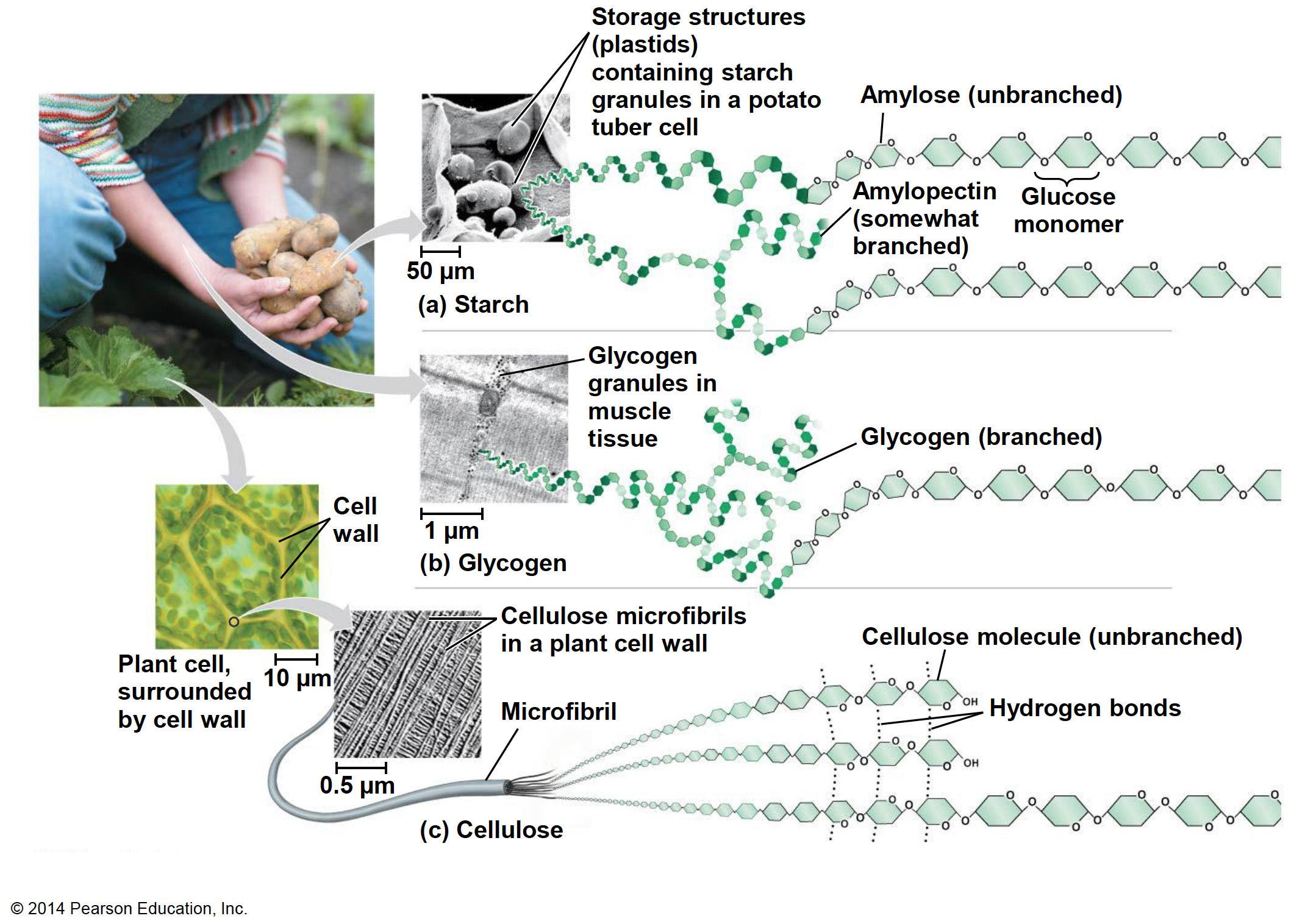
Figure 4.18: Starch, glycogen, and cellulose are the three main homopolysaccharides of importance for our field. Obtained from https://www.sedelco.org/cms/lib/PA01001902/Centricity/Domain/506/05_Lecture_Presentation.pdf
All three molecules are polymers of α- and β D-glucoses. Starch is a polymer of α-D-glucoses linked together by carbons 1 and 4. Glycogen has essentially the same structure, although it has some branches thanks to a bond between carbon 4 and 6 (Figure 4.19).
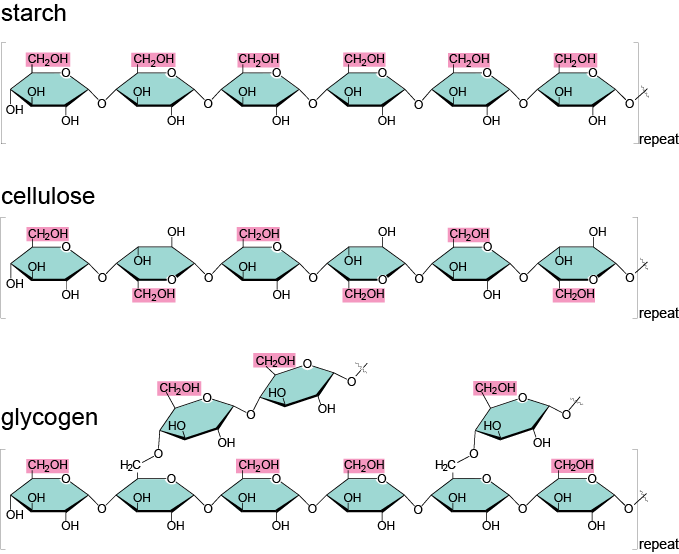
Figure 4.19: Illustration of the 1-4 links between monomers of alpha-D-glucose for starch, plus 4-6 links to form branches for glycogen, and 1-4 links between monomers of beta-D-glucose for cellulose. Obtained from https://biochemikages005.wordpress.com/2014/02/10/carbohydrates/
Before we go on on describing the molecular structure of polysaccharides, it is time to reflect on their significance at the planet scale. Cellulose is the most abundant organic polymer on earth (Klemm et al. 2005). Thanks to the hydrogen bonds between adjacent β-D-glucose polymers, very strong cellulose microfibrils form, themselves bundled into macrofibrils, surrounded by hemicelluloses and lignin (Figure 4.20). Cellulose molecules can be hydrolyzed thanks to the cellulase enzyme, generally secreted by bacteria, although animals such as termites do produce a cellulase. Most mammals only have a limited ability to digest cellulose fibers, and even ruminants and monogastric herbivores use symbiotic bacteria to produce cellulase.
).](pictures/cellwall_carbohydrates.gif)
Figure 4.20: Illustration of Cellulose strands surrounded by hemicellulose and lignin in plant cell walls (Department of Energy’s Genomic, 1986).
So if cellulose is the most abundant molecule on earth, one needs to pause in the structure description of polysaccharides and locate where polysaccharides play a role. Cellulose is the basic structure of plant cell walls. Plant cells, are distinctively different from animal cells because of their cell wall. It is the resemblance with honeycomb cells that Robert Hooke coined the term cell for plants in 1665, the shape being well defined and distinctive thanks to the walls. The cell wall is located externally to the plasma membrane and is synthesized by the cell itself.
Morphologically, the cell wall is formed by layers or sheets. All cells have at least two: middle lamella and primary wall. The middle lamella is synthetized and shared by cells that are contiguous with each other, while the primary cell wall is synthetized and belongs to each cell. In some plant cells, a third thicker layer called secondary cell wall is deposited between the membrane and the primary wall. Most of the wood in the trees correspond to the secondary cell wall (Figure 4.21) (Pacheco Megías, Molist García, and Pombal Diego 2013)
 [@Pacheco_Megias2013-ov].](pictures/cell-walls2.png)
Figure 4.21: Illustration of plant cell walls. In some cells, three layers can be distinguished in the secondary cell wall: S1, S2, and S3 layers are sometimes present, each with a different orientation of its fibers of cellulose. Obtained from the Atlas of Plant and Animal Histology (Pacheco Megías, Molist García, and Pombal Diego 2013).
The outermost layer of the cell wall and the first to form is the middle lamella. It acts as a glue that binds neighboring cells. The middle lamella consists mainly of pectins, although it can be lignified in those cells that have a secondary cell wall. The primary wall consists mainly of cellulose, hemicellulose, pectins, glycoproteins. For the cells that have one, the secondary wall consists mainly of cellulose, hemicellulose and lignins [Figure 4.22; Pacheco Megías, Molist García, and Pombal Diego (2013); Loix et al. (2017)].
![Illustration of the glycans structure of plant cells with primary wall only (A), and plant cells with both primary and secondary walls (B) [@Loix2017-pv].](pictures/cell-walls3.jpg)
Figure 4.22: Illustration of the glycans structure of plant cells with primary wall only (A), and plant cells with both primary and secondary walls (B) (Loix et al. 2017).
Of these different classes, only cellulose is well defined, consisting entirely of β-(1→4)-linked glucan chains. Pectin are highly heterogeneous polysaccharides, traditionally characterized by being relatively easily extracted with hot acid or chelators and by containing a large amount of galacturonic acid residues. Hemicelluloses traditionally comprise the remaining polysaccharides […] (Scheller and Ulvskov (2010))
4.2.3.2 Pectins
Pectins are heteroglycans based on galacturonans, or polygalaturonic acids, i.e. polymers of galacturonic acid monomers. For comparison purposes, the difference between glucose and galacturonic acid is illustrated in Figure 4.23 below. The alcohol functional group of glucose on C6 is oxidized into a carboxylic acid group, and the hydroxy on C4 changes side. The main role of pectin is to give physical strength to the plant and to provide a barrier against the outside environment (Harholt, Suttangkakul, and Vibe Scheller 2010). Pectins also hold cells together. Fruit ripening (becoming softer) or leaf fall, are in part due to the decomposition of pectins by pectinase enzymes. Pectins also seem to play a role during seed germination, and as such also have an energy storage role, particularly thanks to the galactans and arabinans (Harholt, Suttangkakul, and Vibe Scheller 2010; Scheller and Ulvskov 2010)
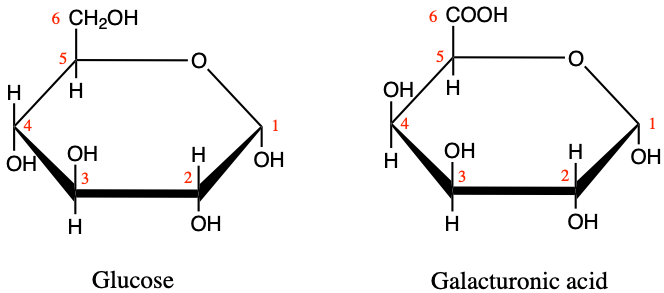
Figure 4.23: Illustration of the differences between alpha-D-glucose and D-galacturonic acid monomers.
Harholt, Suttangkakul, and Vibe Scheller (2010) classify pectins in four categories (Figure 4.24):
- the homogalacturonans (HG), which are relatively homogeneous galacturonans, although some acetyl (-C=O-CH3) or methyl (-CH3, more details herein) groups can be added. These are the most abundant, ~65% (Harholt, Suttangkakul, and Vibe Scheller 2010)
- the xylogalacturonans (XGA), for which some xylose monomers are added to the the galacturonan chain thanks to the glycosidic bonds. XGA appear to be minor components of pectins.
- the Rhamnogalacturonans II (RGII), which still hold the galacturonan as the basic chain, but with complicated carbohydrate chains, containing rhamnose monomers in particular. RGII appear to be minor components of pectins.
- and the Rhamnogalacturonans I (RGI), for which rhamnose monomers alternate between galacturonic acids and that side carbohydrate side chains of arabinans and galactans. RGI constitute between 20-35% of the pectins.
![Illustration of the general types of pectins. Notice that the common structure or pectin backbone (but for RGI) is the polymer of galacturonic acids, or galacturonan, to which, quite a diversity of monomers participate resulting in the large heterogeneity of these heteroglycans [@Harholt2010-ox].](pictures/pectins.jpg)
Figure 4.24: Illustration of the general types of pectins. Notice that the common structure or pectin backbone (but for RGI) is the polymer of galacturonic acids, or galacturonan, to which, quite a diversity of monomers participate resulting in the large heterogeneity of these heteroglycans (Harholt, Suttangkakul, and Vibe Scheller 2010).
Again, this information is provided to expose readers to the extraordinary diversity of carbohydrates, and are not meant to be known in great details. It is important to remember that in addition to homoglycans, there are galactorunans, on which pectins are based.
4.2.3.3 Hemicelluloses
Hemicelluloses are heteroglycans or heteropolysaccharides. The hemicellulose term was coined at a time when the structures were not well understood and biosynthesis was completely unknown. Hemicellulose is recognized as a group of wall polysaccharides that are characterized by being neither cellulose nor pectin and by having β-(1→4)- linked backbones of glucose, mannose, or xylose (Figure 4.25). These glycans all have the same equatorial configuration at C1 and C4 and hence the backbones have significant structural similarity (Scheller and Ulvskov 2010). For those of you who are curious about the ‘equatorial configuration’ term used here, this has to do with the steric configuration of the hydroxy groups in the cyclic configuration of monosaccharides. This was not even introduced in this chapter, although it is an important consideration for chemists to characterize carbohydrates!
![Illustration of the general types of hemicelluloses, which vary among species and plant groups. Notice the nomenclatures ending in *-an*, suggesting polysaccharides. OMe, represents methyl groups; Ac, represents acetyl groups; “Fer” represents esterification with ferulic acid (3-methoxy-4-hydroxycinnamic acid) [after @Scheller2010-ep].](pictures/hemicelluloses_final.png)
Figure 4.25: Illustration of the general types of hemicelluloses, which vary among species and plant groups. Notice the nomenclatures ending in -an, suggesting polysaccharides. OMe, represents methyl groups; Ac, represents acetyl groups; “Fer” represents esterification with ferulic acid (3-methoxy-4-hydroxycinnamic acid) (after Scheller and Ulvskov 2010).
The most important biological role of hemicelluloses is their contribution to strengthening the cell wall by interaction with cellulose microfibrilsand, in some walls, with lignin (e.g., Figure 4.21). All the hemicelluloses show differences in structural details between different species and in different cell types within plants (Figure 4.25).
In summary:
Polysaccharides
- Polysaccharides or glycans are formed by the polymerization of mostly hexose monomers, although pentoses are sometimes involved, via the glycosidic bond
- The atoms involved in the glycosidic bonds determine whether the polymer is linear or branched, and ultimately determines the type of polysaccharides
- The energy stored on polysaccharides is not available unless the hexoses are liberated one by one or two by two (starch → maltose) from the polysaccharides chains
- Cellulose is the most abundant organic polymer on earth present in all plant cell walls
- Pectins are heteroglycans based on galacturonans largely present in the primary wall of plant cells
- Hemicelluloses are a losely defined group with little strength present in cell walls intertwined with cellulose fibers
Cellulose, pectins and hemicelluloses all agregate in plant cell walls alongside the ubiquitous lignin which stiffens the wall as we shall see. Although lignin is made of CHO, and is closely associated with polysaccharides, it technically does not belong to the carbohydrate family as its monomers are not oses, but generally phenylpropanoid, and the polymerization does not involve the glycosidic bond. For this reason, lignin is presented in section 4.6 dedicated to phenolics in this chapter.
4.2.4 Other important carbohydrates
It would be erroneous to leave out some additional mono- or polyssaccharrides out as some of them play a very significant role in biology and ecology. In a way, they correspond to the exceptions that confirm or rather complete the rule. So far, we have summarized monosaccharides with the general formula (CH2O)n, to essentially be mostly C5 and C6 molecule where the average carbon is bonded to an hydroxy functional group and a hydrogen atom. And that these monosaccharides have the tendency to form 5 or 6 atom rings. Well, it turns out that on this general configuration, some of the hydroxy groups are replaced by other functional groups.
The most famous one is probably is deoxybose, as it replaces ribose, as already mentioned above and illustrated again below (Figure 4.26).
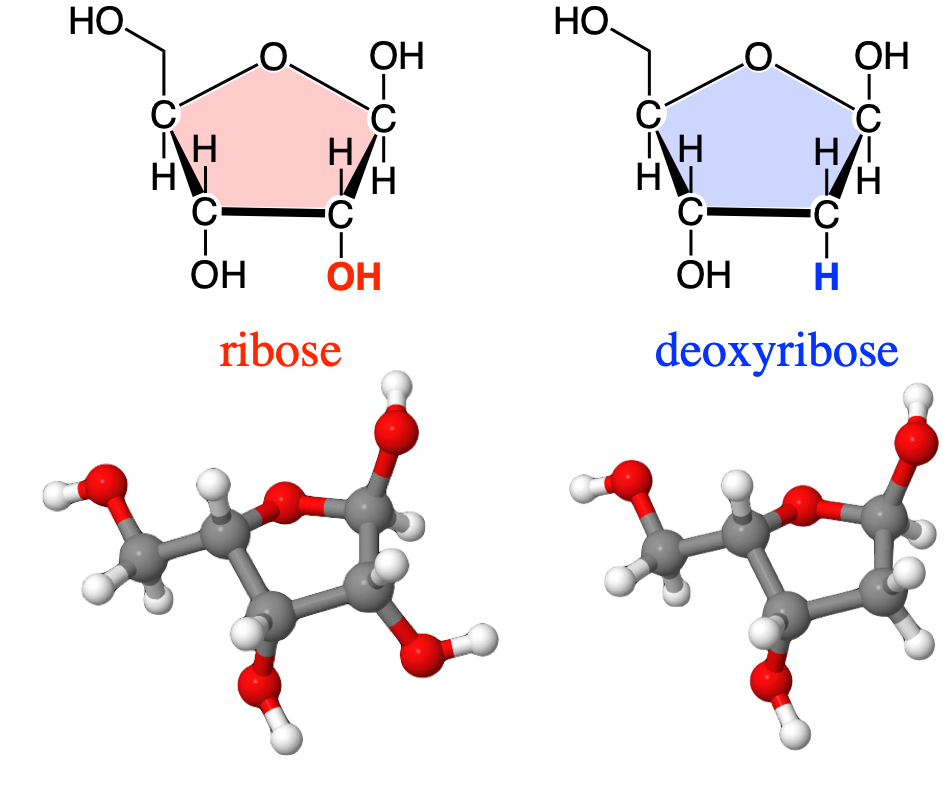
Figure 4.26: Replacement of a hydroxy group of ribose by hydrogen, effectively removing an oxygen atom or ‘deoxy-ing’ the ribose, hence the formation of deoxyribose
Several others that need mentioning are illustrated below. The first one is glucosamine where carbon number 2 has been replaced by an amine group. Glucosamine is a precursor of glycosylated proteins and lipids (glycosylated means that a sugar is linked with a protein/lipid other substituent via a glycosidic bond). When an acetyl group is added to the amine group of a glucosamine (via an amide bond), the resulting carbohydrate is called N-acetylglucosamine (Figure 4.27).
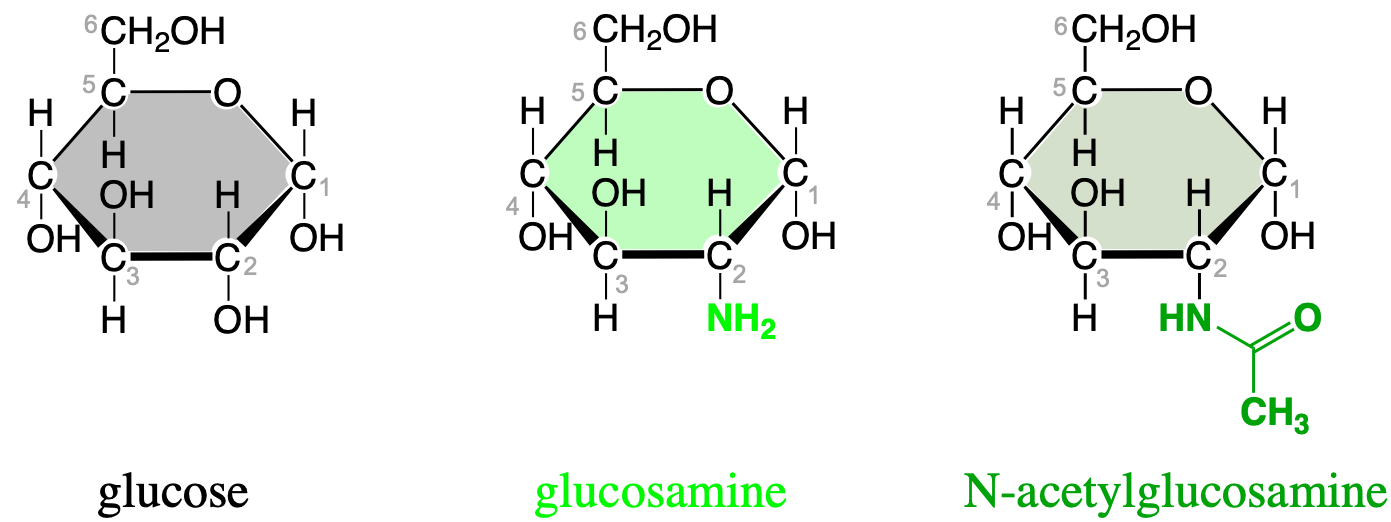
Figure 4.27: Important additional monosaccharides where the hydroxy group has been replaced by an amine and an N-acetylamine
Two of these N-acetylglucosamine bonded via a glycosic bond form the monomer for chitin (Figure 4.28), i.e., the polysaccharide forming the exoskeleton of arthropods, such as crustaceans and insects, the radulae of molluscs, cephalopod beaks, and the scales of fish and lissamphibians [Wikipedia contributors (2019e); Figure 4.29].
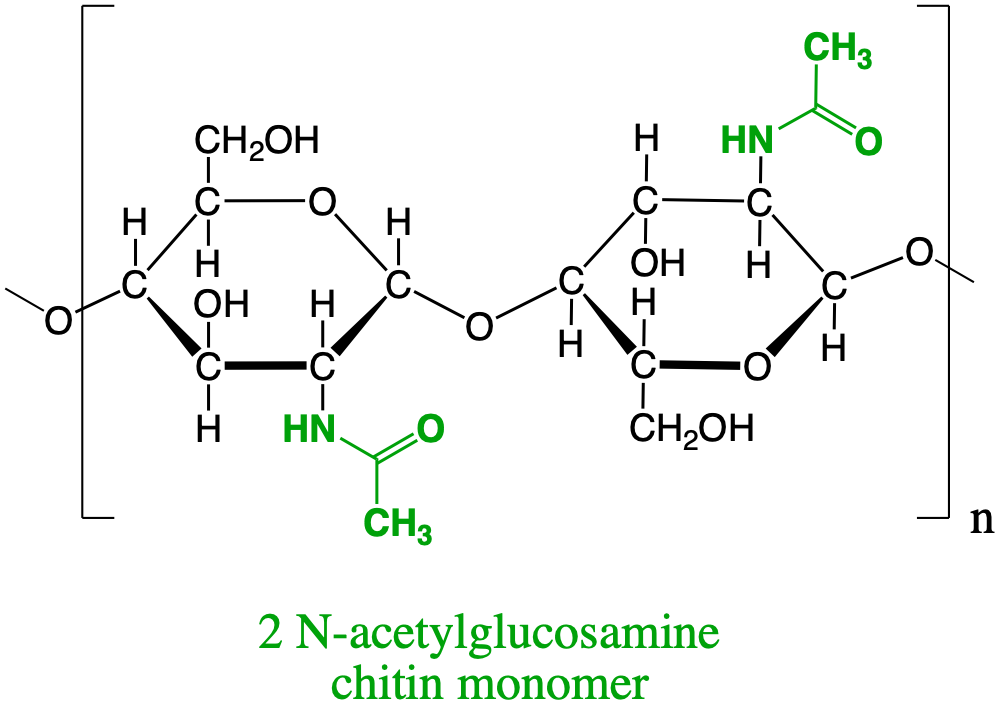
Figure 4.28: N-acetylamine dimer forming the basis for the chitin polysaccharide that serves as exoskeleton of many invertebrates
The exoskeleton of these macroinvetebrates possesses excellent mechanical properties in terms of stiffness-todensity ratio and fracture toughness (Nikolov et al. 2011). This is explained by the microstructure of the exoskeleton, and how the chitin nanofibrils are put together (Figure 4.29).
![Exoskeleton of the American lobster (*Homarus americanus*) formed by seven levels of microstrucutures of the nanofibrils of chitin, polysaccharide of N-acetylglucosamine [@Nikolov2011-je]](pictures/chitin-lobster.jpg)
Figure 4.29: Exoskeleton of the American lobster (Homarus americanus) formed by seven levels of microstrucutures of the nanofibrils of chitin, polysaccharide of N-acetylglucosamine (Nikolov et al. 2011)
Deoxygenation of the alcohol group of carbon 6 of glucose yields quinovose or 6-deoxyglucose (Figure 4.30). The methyl radical can become sulfanated by a sulfo- radical, to yield sulfoquinovose. Sulfoquinovose is one of the backbone sugars for glycolipids that form the innermembrane of thylakoids in chloroplasts (more details in section 4.5.5.3). The molecule quinovose is a sugar moiety of the quinovin molecule, extracted from the bark of the tree of the cinchena genus in South America. The local Quechuan name is kina, and the new kina, is a quina nova, hence the word quinovin by contraction. And the sugar or ose of the quinovin is thus named a quinovose.
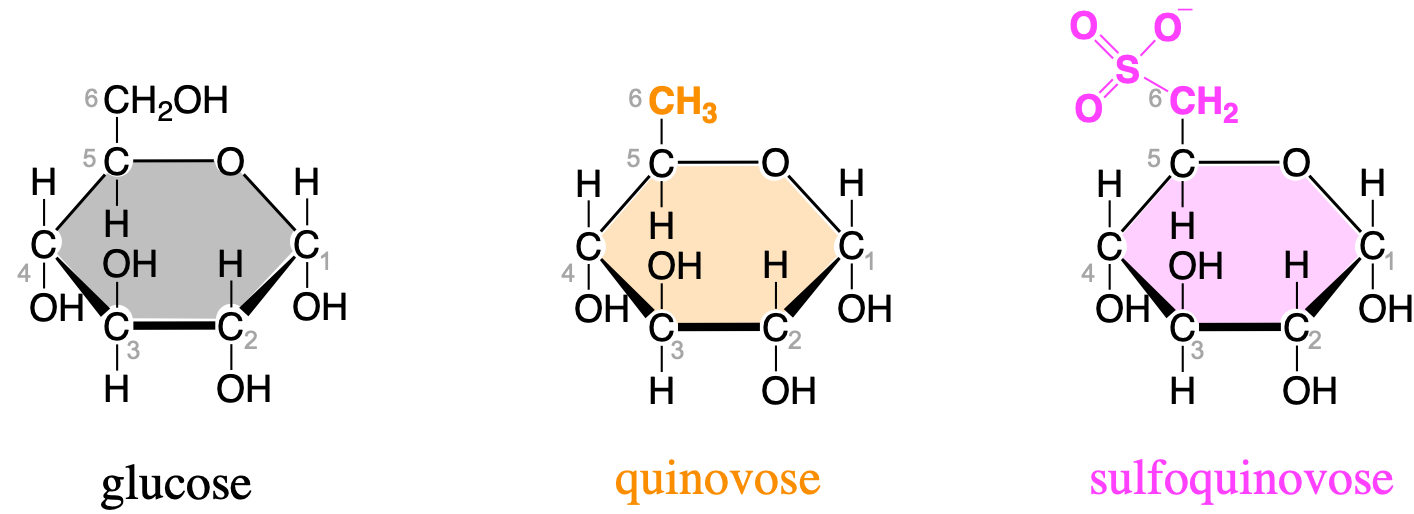
Figure 4.30: Glucose, quinovose, and sulfoquinovose as important monosaccharides used as building blocks for glycolipids forming the inner membranes of thylakoids in chloroplasts
Lastly, carbohydrates play a major role in the communication between cells as carbohydrates small chains are often attached to membrane proteins and lipids, in which case proteins and lipids are referred to as glycoproteins and glycolipids, respectively (more details below).
Learning outcomes
at the end of this section on carbohydrates, you should be able to:
Monosaccharides:
- Recognize that each atom has on average 4 electrons for itself, making monosaccharides the ideal molecule to store and release high energy electrons
- Recognize that the consequence is the presence of aldehyde and ketone functional groups which allow the cyclization of pentoses and hexoses
- Recognize that the release of energy can only occur when they are in the aldose chain form
- Know that their formula is (CH2O)n where 3 < n < 6, generally, and the formula of glyceraldehyde
- Recognize that small differences in the position of hydroxy, and in the cyclization of the C5 and C6 make for different monosaccharides
- Recognize that thanks to all the hydroxy groups, monosaccharides are extremely soluble in water.
- Draw a glucose molecule by heart
Disaccharides:
- Draw a glycosidic bond between consecutive glucose molecule
- Explain the concept of reducing and non-reducing sugars
- Recognize that dimers of hexoses are the energy transport molecules
- Know that sucrose is a dimer of glucose and fructose as is a non-reducing sugar
Polysaccharides
- Know that polysaccharides are generally polymers of hexoses bonded together thanks to the glycosidic bond
- Recognize that the atoms involved in the glycosidic bonds determine the type of polysaccharides
- Recognize that the energy stored on polysaccharides is not available unless the hexoses are liberated one by one or two by two (starch → maltose) from the polysaccharides chains
- Know that cellulose is the most abundant organic polymer on earth
- Know that pectins are heteroglycans based on galacturonans while hemicellulose are a losely defined group
- Recognize that chitin that forms the exoskeleton of arthropods is an polymer of N-acetylglucosamines, the latter being an aminated version of glucose
4.3 Proteins
The second molecular family we choose to present is proteins.
Etymology Corner The word proteins used in English results from the French word protéine first coined by Dutch organic and analytical chemist Gerardus Johannes Mulder in an article published in 1838 (Mulder 1838), and later translated in German as Protein in 1839. Both words are based on the ancient greek πρωτειοζ or proteioz (~primary), because Mulder thought that the ‘organic acids making protéines appeared to be the primitive or principal substance that plants prepare for herbivores, which the latter provide to the carnivores’ (Mulder 1838; Hartley 1951).
Exercise 4.3 Draw some basic Amino acids and polypeptides
In the JSME editor below, draw the molecules listed underneath. You may also render them in 3D in JSmol by going directly to JSmol demo page and click on the “JSME embedded with JSmol, for 2D⇄3D conversion” link.
Draw the simplest amino acid glycine. Its R group is H (Ans: NCC(=O)O)
Draw the alanine amino acid. Its R group is a methyl (Ans: CC(N)C(=O)O)
Draw the Phenylalanine amino acid. Its R group is a methylated phenyl group (Ans: NC(Cc1ccccc1)C(=O)O)
Draw the cysteine amino acid. Its R group is a thiol (Ans: NC(CS)C(=O)O)
Draw the lysine amino acid. Its R group is a butylamine (Ans: NCCCCC(N)C(=O)O)
Draw the serine amino acid. Its R group is a methanol (Ans: NC(CO)C(=O)O)
Draw the valine amino acid. Its R group is an isopropyl (Ans: CC(C)C(N)C(=O)O)
Draw the polypeptide valine-glycine-phenylalanine-valine (Ans: CC(C)C(N)C(=O)NCC(=O)NC(C(=O)NC(C(=O)O)C(C)C)c1ccccc1)
Draw the polypeptide valine-phenylalanine-glycine-valine (Ans: CC(C)C(N)C(=O)NC(C(=O)NCC(=O)NC(C(=O)O)C(C)C)c1ccccc1)
Proteins correspond to single, or assemblages of, polymers of amino acids referred to as polypeptide chains.
This chapter is still under construction
4.4 Nucleic Acids and Nucleotides
The third molecular family we choose to present are Nucleic Acids. The term nucleic acid is the overall name for the DeoxyriboNucleic Acid (DNA) and the RiboNucleic Acid (RNA). DNA and RNA carry the genetic code and are present in every living cell on this planet (viruses seem to have some variations on that). Nucleic acids are polymers of nucleotides, and as such are polynucleotides. Nucleic acids are unbranched molecules that generally are very large, and in fact the longest among all macromolecules, accounting up to 247 million monomers in a human chromosome (Wikipedia contributors 2021a).
It was Friedrich Miescher, Swiss physician and biologist who first isolated what he called nuclein from nuclei of white blood cells he had access to from pus-coated patient bandages (Miescher 1871). Miescher came across this “substance from the cell nuclei that had chemical properties unlike any protein, including a much higher phosphorous content and resistance to proteolysis (protein digestion). […] Miescher’s discovery of nucleic acids was unique among the discoveries of the four major cellular components (i.e., proteins, lipids, polysaccharides, and nucleic acids) in that it could be dated precisely… [to] one man, one place, one date” (“Discovery of DNA Double Helix: Watson and Crick,” n.d.).
Nucleic acids are made of the C,H,O,N, and P atoms with a relatively high concentration of N and P compared to any other molecular family. This suggests that the combined and concentrated presence of N and P makes for very special molecules.
4.4.1 Nucleotides as monomers of nucleic acids
DNA and RNA are polymers of four nucleotide monomers. Each of them is made of three moeities bonded together: a phosphate, a pentose, and a nucleobase, the latter sometimes referred to as a nitrogenous base (Figure 4.31). The names of the nucleobases (Adenine, Guanine, Cytosine, Thymine - for DNA, and Uracil - for RNA) are sometimes used to describe the nucleotide itself, which might be confusing…
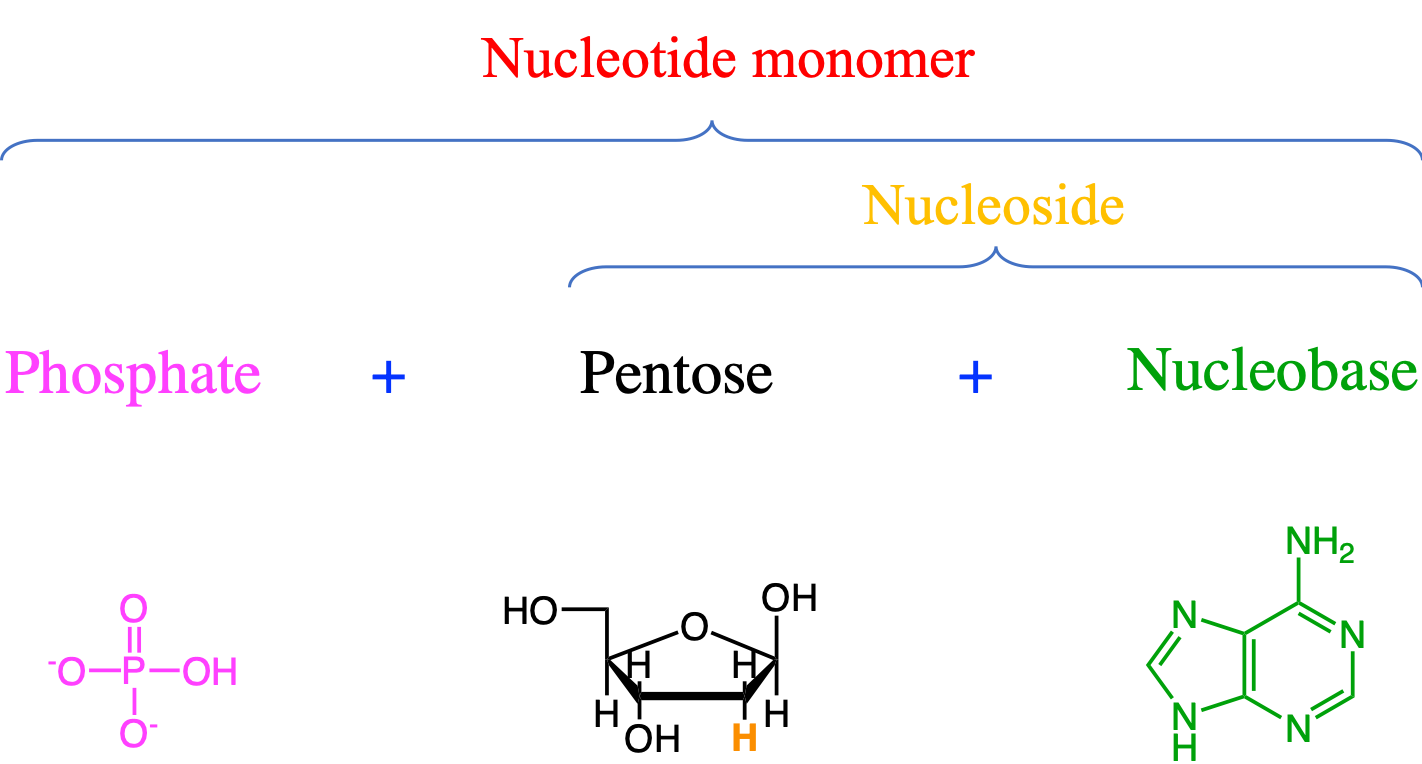
Figure 4.31: The basis structure of the generic monomer of a nucleic acid is made of phosphate, pentose, and nucleobase moieties. The nucleobase in the figure is Adenine, and the pentose is a deoxyribose
It is important to be able to recognize the differences between the nucleobases, nucleosides, and nucleotides. Nucleobases or otherwise named nitrogenous bases because of the large density of nitrogen atoms are divided into purines (5 N atoms for 3-4 C atoms) and pyrimidines (3 N atoms for 4-5 C atoms). Purines and pyrimidines are heteroarenes (see Figure 3.10 and section 3.1.3), that have aromatic cycles, where some of the carbon atoms have been replaced by nitrogen atoms. Adenine, Guanine, and Cytosine are common to DNA and RNA, while Thymine is only present in DNA, and Uracil only present in RNA. Both purines and pyrimidines are ‘flat’ molecules, which can be paired together thanks to hydrogen bonds (details below).
 [@Blausencom_staff2014-gi]](pictures/Nucleobases.png)
Figure 4.32: The purines and pyrimidines form the nucleobase moieties of nucleotide monomers. Because of the aromatic nature of these moieties, the nucleobases are flat, allowing for pairing using hydrogen bonds After BruceBlaus, CC BY 3.0 (Blausen.com staff 2014)
The condensation reaction between a nucleobase and a pentose on the 1’ carbon results in a nucleoside (Figure 4.33). To differentiate between the carbons of the nucleobases and those of the pentose, geneticists have added a “prime” or apostrophy next to the carbon number, hence the 1’ Figure 4.33.

Figure 4.33: The condensation reaction between a pentose and a nucleobase on the carbon 1’ corresponds to an N-glycosidic bond and results in the formation of a nucleoside. The nucleobase in the figure is Adenine, and the pentose is a deoxyribose
The condensation between a nucleoside and a phosphate moiety forms a nucleotide (Figure 4.34). The bond between the 5’ carbon of the pentose with phosphate is a phosphoester bond.

Figure 4.34: The condensation reaction between a phosphate moiety and a nucleoside results in the formation of a nucleotide monomer. The bond between the phosphate and the nucleoside moieties is a phosphoester bond. The nucleobase in the figure is Adenine, and the pentose is a deoxyribose
Nucleic acids are formed by the polymerization of nucleotide monomers. This polymerization is made possible thanks to the condensation between the phosphate moeity of one nucleotide with the hydroxy on 3’ of the pentose moiety of another nucleotide (Figure 4.35). The polymerization occurs at the 3’ end, of in the case of Figure 4.35 by adding a nucleotide at the bottom. The phosphate moiety in a nucleic acid chain is bonded to 2 pentose moieties and this bond is referred to as a phospho-diester bond. This bond is crucial and extremely rigid and provide what is referred to as the sugar-phosphate backbone.
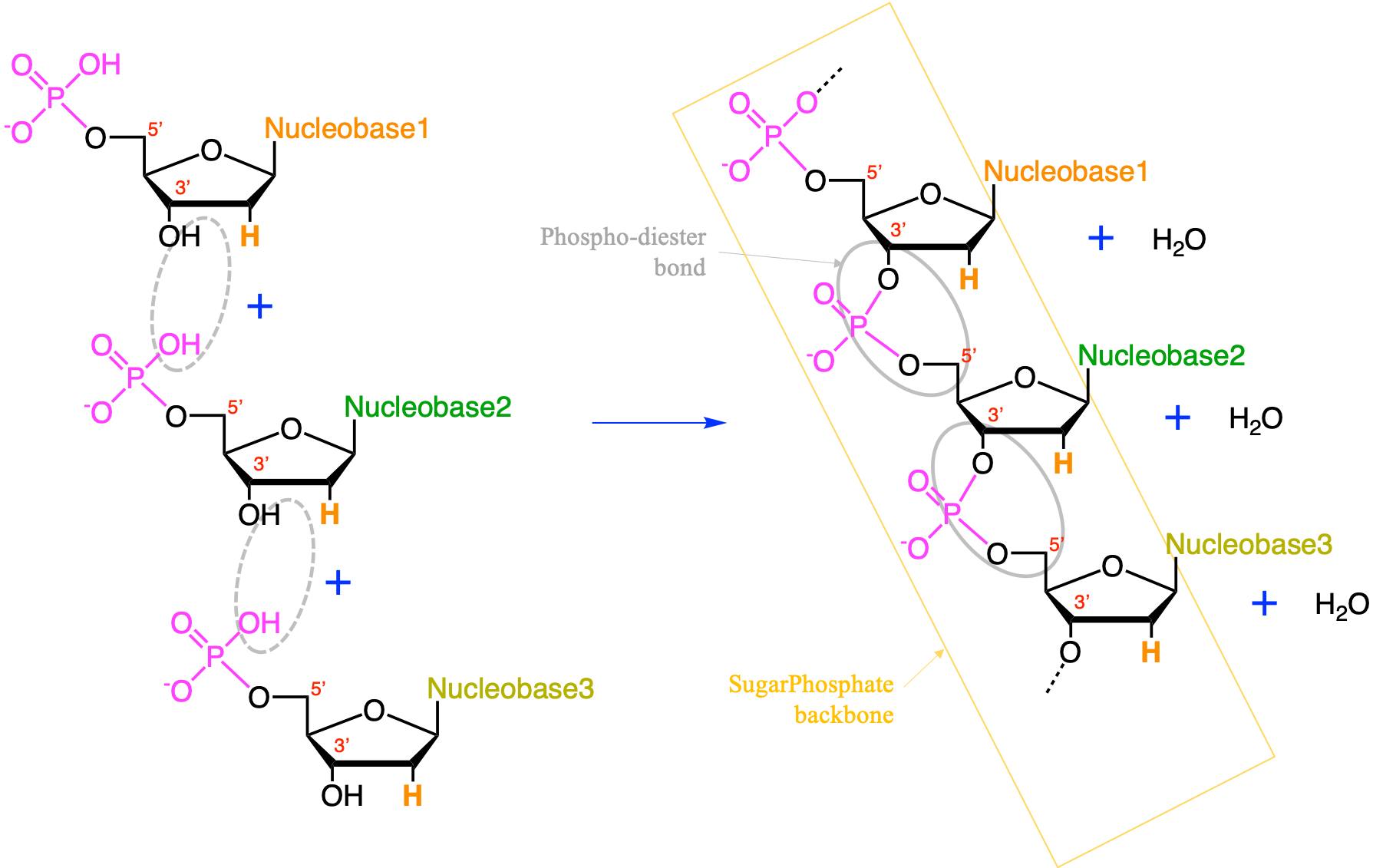
Figure 4.35: The condensation reaction between consecutive nucleotides between the phosphate moiety and the carbon 3’ results in the formation of a nucleic acids. The bond between the phosphate moiety and the two pentoses is a phospho-diester bond. The phosphate-pentose chain held togeter by the phospho-diester bond is referred to as the sugar-phosphate backbone. The pentose is a deoxyribose
In both RNA and DNA, the sugar-phosphate backbone results in the 3D formation of α-helix molecules. In Figure 4.36, the sugar-phosphate backbone has been illustrated as a ribbon. Notice the phosphate moeiety on the outside of the ribbon forcing the nucleoside and thus the nitrogenous bases to point into the helix and stacking on top of each other. It takes about 10 polynucleotides to make a full circle.

Figure 4.36: Illustration of the double-helix double-stranded molecule of DNA with 10 nucleotides polymerized for each strand
4.4.2 DNA and RNA
The DeoxyriboNucleic Acids (DNA) and the RiboNucleic Acids (RNA) have several fondamental differences:
- the pentose for RNA is a Ribose, and for DNA it is a Deoxyribose (Figure 4.31 and 4.37)
- one of the pyrimidine nucleobases is only found in DNA, i.e., Thymine, and the other is only found in RNA, and that is Uracil. The difference between the two is one methyl group missing on Uracil (Figure 4.32 and 4.38)
- DNA is a double-stranded molecule, while RNA is single-stranded (Figure 4.38)
Figure 4.37: Replacement of a hydroxy group of ribose by hydrogen, effectively removing an oxygen atom or ‘deoxy-ing’ the ribose, hence the formation of deoxyribose
](pictures/DNA-RNA-EN.png)
Figure 4.38: Differences between RNA (left) and DNA (Right) illustrating the single-stranded structure of RNA and the Uracil nucleobase, vs. the double-stranded structure of DNA and the thymine nucleobase that replaces the uracil. by Roland1952, CC BY-SA 3.0
The double helix […] double-stranded DNA, […] is composed of two linear strands that run opposite to each other, or anti-parallel, and twist together. Each DNA strand within the double helix is a long, linear molecule made of smaller units called nucleotides that form a chain. […] The two helical strands are connected through interactions between pairs of nucleotides, also called base pairs. Two types of base pairing occur: nucleotide A pairs with T, and nucleotide C pairs with G (“Double Helix,” n.d.).
![Two hydrogen bonds connect T to A; three hydrogen bonds connect G to C. The sugar-phosphate backbones (grey) run anti-parallel to each other, so that the 3’ and 5’ ends of the two strands are aligned. Figure and caption from [@noauthor_undated-pi]](pictures/DNA-double-helix-nature.jpg)
Figure 4.39: Two hydrogen bonds connect T to A; three hydrogen bonds connect G to C. The sugar-phosphate backbones (grey) run anti-parallel to each other, so that the 3’ and 5’ ends of the two strands are aligned. Figure and caption from (“Discovery of DNA Double Helix: Watson and Crick,” n.d.)
A unique pairing between Adenine (A) and Thymine (T) nucleotides, and between Guanine (G) and Cytosine (C) nucleotides in DNA, and, between Adenine and Uracil (U) during RNA transcription is at the core of the replication of the genetic code and its transcription into the synthesis of proteins. The pairing only occurs between a pyrimidine and a purine bases. This is associated with the space available within the double helix (20 Å): not enough for two purines to fit within the helix and too much space for two pyrimidines to get close enough to each other to form hydrogen bonds.
The unique pairing between A and T, C and G, and A and U is possible thanks to:
- the sugar-phosphate backbone structure which leads the nucleotide bases to point into the helix for a diameter of 20 Å leaving enough room for a purine and a pyrimidine moeities to face each other at the center (Figure 4.36)
- the planar structure of the nitrogenous bases due to the aromatic rings, and the location of functional groups that place the amine and carbonyl groups outward on a same plane (Figure 4.36 and 4.32)
- the high electronic density associated with the lone pairs of electrons on the oxygen of the carbonyl groups and the nitrogen of the amine groups that open the possibility for the creation of hydrogen bonds between (Figure 4.39)
- C=O····H-N
- N-H····N
This results in the possibility of forming of three hydrogen bonds between C and G, while only two hydrogen bonds can occur between A and T, and A and U, hence the unique pairing described above. This also results in the fact that the two strands of the DNA molecule are a mirror image of each other although they run opposite or anti-parallel to each other.
4.4.2.1 Quick recall on DNA replication
It is impossible to present nucleic acids structure and not presenting any of their function, although this is objectively secondary as the main goal of this chapter is to direct why living organisms need nutrients, and in what molecules these atom eventually end up. The structure of DNA is all geared towards the replication and the transcription of the genetic code. The goal here is not to give an in depth course on replication, but provide enough of the details.
In simple terms, replication involves use of an existing strand of DNA as a template for the synthesis of a new, identical strand (Pray 2008).
For this to happen the double helix needs first to be unwinded and maintained as such. Then DNA polymerases can add deoxynucleotides at the 3’ end.
This chapter is still under construction
Exercise 4.4 Draw some basic Nucleobases and nucleotides
In the JSME editor below, draw the molecules listed underneath. You may also render them in 3D in JSmol by going directly to JSmol demo page and click on the “JSME embedded with JSmol, for 2D⇄3D conversion” link.
Purine nucleobases
Draw the adenine nucleobase.
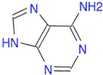 (Ans: C/1=N/C2=C(C(N)=N1)/N=C)
(Ans: C/1=N/C2=C(C(N)=N1)/N=C)Draw the guanine nucleobase.
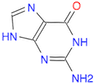 (Ans: C1(/N)=N=C(C(=O)N1)=C/N2)
(Ans: C1(/N)=N=C(C(=O)N1)=C/N2)
Pyrimidine nucleobases
Draw the cytosine nucleobase.
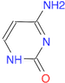 (Ans: C1(=O)/N=C(N)=C/N1)
(Ans: C1(=O)/N=C(N)=C/N1)Draw the thymine nucleobase.
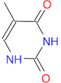 (Ans: C1(=O)NC(=O)/C(C)=C)
(Ans: C1(=O)NC(=O)/C(C)=C)Draw the uracil nucleobase.
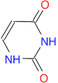 (Ans: C1(=O)NC(=O)/C=C)
(Ans: C1(=O)NC(=O)/C=C)
Nucleotides: Nucleoside monophosphates
- Draw the deoxyadenosine monophosphate, i.e., the DNA nucleotide monomer that contains the adenine nucleobase (Ans:C1C(C(OC1N2C=NC3=C(N=CN=C32)N)COP(=O)(O)O)O)
https://www.britannica.com/science/acid
Nucleotide, any member of a class of organic compounds in which the molecular structure comprises a nitrogen-containing unit (base) linked to a sugar and a phosphate group. The nucleotides are of great importance to living organisms, as they are the building blocks of nucleic acids, the substances that control all hereditary characteristics.
In the two families of nucleic acids, ribonucleic acid (RNA) and deoxyribonucleic acid (DNA), the sequence of nucleotides in the DNA or RNA codes for the structure of proteins synthesized in the cell. The nucleotide adenosine triphosphate (ATP) supplies the driving force of many metabolic processes. Several nucleotides are coenzymes; they act with enzymes to speed up (catalyze) biochemical reactions.
The nitrogen-containing bases of nearly all nucleotides are derivatives of three heterocyclic compounds: pyrimidine, purine, and pyridine. The most common nitrogen bases are the pyrimidines (cytosine, thymine, and uracil), the purines (adenine and guanine), and the pyridine nicotinamide.
Nucleosides are similar to nucleotides except that they lack the phosphate group. Nucleosides themselves rarely participate in cell metabolism.
Adenosine monophosphate (AMP) is one of the components of RNA and also the organic component of the energy-carrying molecule ATP. In certain vital metabolic processes, AMP combines with inorganic phosphate to form ADP (adenosine diphosphate) and then ATP. The breaking of the phosphate bonds in ATP releases great amounts of energy that are consumed in driving chemical reactions or contracting muscle fibres. Cyclic AMP, another nucleotide, is involved in regulating many aspects of cellular metabolism, such as the breakdown of glycogen.
A dinucleotide, nicotinamide adenine dinucleotide (NAD), participates in many oxidation reactions as an electron carrier, along with the related compound nicotinamide adenine dinucleotide phosphate (NADP). These substances act as cofactors to certain enzymes.
We have not mentioned this molecule just yet because it is a complicated molecule. Yet, it plays a crucial role in many catalytic reactions
Structure of coenzyme A: 1: 3′-phosphoadenosine. 2: diphosphate, organophosphate anhydride. 3: pantoic acid. 4: β-alanine. 5: cysteamine. By NEUROtiker - Own work, Public Domain, https://commons.wikimedia.org/w/index.php?curid=1555659
This chapter is still under construction
4.5 Lipids
Lipids are fatty acids and their derivatives, and substances related biosynthetically or functionally to these compounds (W. W. Christie 1987).
This is the best concise and satisfying definition! The scientific term “lipid” comes from the Greek “lipos” which referred to animal fat or vegetable oil. Lipids are mainly made of C and H atoms, but do also contain O, N, and P. So it is important to remember that lipids are made of CHONP. Lipids are a very heterogeneous group of molecules and are defined in part from their propensity to be soluble in non-polar solvents (no net dipole as a result of the opposing charges in the solvent molecules). In other words, lipids do not (or not easily) dissolve in water.
Contrary to carbohydrates, proteins, or nucleic acids, lipids are not obvious polymers of identified and clearly defined monomers. Rather, lipids are assemblages of well identified building blocks and backbones bonded together with ester, ether, and amide bonds. There are two main types of building blocks resulting in two major types of lipids: lipids built from fatty acid blocks (acyl groups) and lipids based from isoprene building units (ringed or not isoprene groups). Because there is no polymerization, lipids are relatively small molecules compared to polysaccharides, proteins, or nucleic acids.

Figure 4.40: Common everyday ingredients containing lipids. (obtained from http://blesslaboratory.com/index.php/services/oil
The carbons of lipids are generally a lot more reduced (have more electrons for themselves) than the ones of carbohydrates. For the latter, there are just about as many oxygen atoms as there are carbons, as a legacy of how they are formed during photosynthesis (details in chapter 6). Because of the number of oxygen atoms and their reactivity, carbohydrates are only able to form relatively short 5 and 6 carbon monomers, which tend to readily assemble into rings. Polymerization is what allows carbohydrates to form very large molecules.
Lipids aliphatic chains have almost no oxygen atoms instead, and always strategically located near the ends of the chains. Consequently, the carbons of the hydrocarbon chains are not as prompt to react together. The result is that it becomes possible to have longer hydrocarbon molecules (commonly C16 to C22, compared to C5 and C6 carbohydrates). The aliphatic chains are relatively chemically inert and interact together by low level van der Waals forces. These long aliphatic chains are the reasons for the mostly hydrophobic character of lipids (Figure 4.40).
However, the fatty acid-based lipids are amphipathic (also referred to as amphiphilic), i.e., that they have both hydrophilic and hydrophobic ends. The hydrophobic end or hydrophobic tail corresponds to the long aliphatic chain of the fatty acid residue. The hydrophilic end or hydrophilic head is associated with the other building blocks made of ionic and polar groups that include ester and amide bonds, the backbone, and other polar radicals (details below). The amphiphilic nature of some lipids allows them to form structures such as vesicles, multilamellar/unilamellar liposomes, or membranes in an aqueous environment (Wikipedia contributors 2019a).
Overall, lipids function as essential structural components of membranes, as signalling molecules, as chemical identifiers of specific membranes and as energy storage molecules (Meer, Voelker, and Feigenson 2008). Thousands of lipid molecules have been listed and an entire scientific discipline called lipidomics is dedicated to lipids structure and function! Rigorous classifications have been proposed (e.g., Fahy et al. (2005), Fahy et al. (2009)), and gateways on lipid research and updates are available (e.g., lipidmaps). Our goal here is to present enough of what lipids are and do.
Overall lipids may be divided into eight categories: fatty acids, glycerolipids, glycerophospholipids, sphingolipids, saccharolipids, and polyketides (derived from condensation of acyl subunits); and sterol lipids and prenol lipids (derived from condensation of isoprene subunits) (Wikipedia contributors 2019a)
4.5.1 Overview of fatty acid- or acyl-based lipids
In this category, are included fatty acids, glycerolipids, glycerophospholipids, saccharolipids, and sphingolipids. They all have in common the presence of long aliphatic carbon chains forming ‘tails’ of the molecules. The average carbon of a fatty acid chain is a methylene (-CH2-) such that each carbon atom has 6 electrons for itself (Figure 4.41). Consequently, lipids are, among the macromolecules, those which can store and release the most energy per carbon atom!
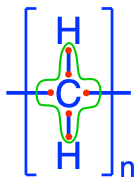
Figure 4.41: Electron allocation of a generic fatty acyl group (CH2)n. The group -CH2- is referred to as a methelene group
Lipids share with nucleic acids the ‘building block’ structure, in that they are built of identified building blocks. The quintessential acyl-based lipid is made of two fatty acids forming the hydrophobic tail end, a backbone, a phosphate or hexose, and a polar group. The two latter building blocks form the hydrophilic head, which tends to be a lot shorter than the hydrophobic end as illustrated in Figure 4.42 below.
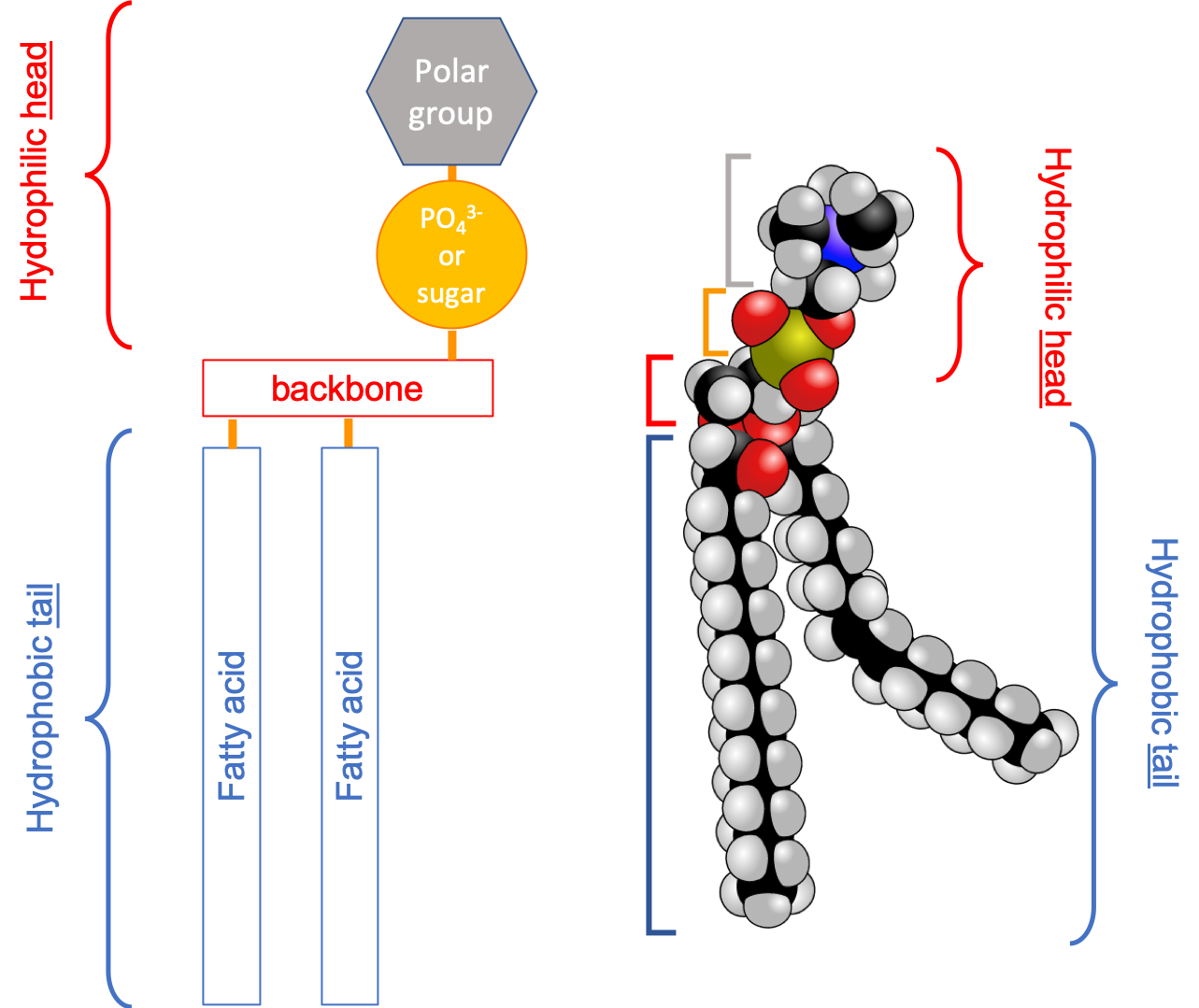
Figure 4.42: Schematic of the quintessential fatty acid based lipid illustrating the amphipathic nature, and the different building blocks
From this simple construction, thousands of acyl-based lipid molecules exist following a wide variation on the fatty acids themselves, the three types of backbones, and on the polar groups (nature and number). And there are lots of exception to this general rule (e.g., Fahy et al. 2005, 2009). Nonetheless, Figure 4.43 summarizes how acyl-based lipids are constructed and how some of the classification has been derived. It reads from the bottom to top.
The first stage of molecules having only one of the building blocks are the fatty acids. There are so many of them that they are classified as a lipid group by themselves.
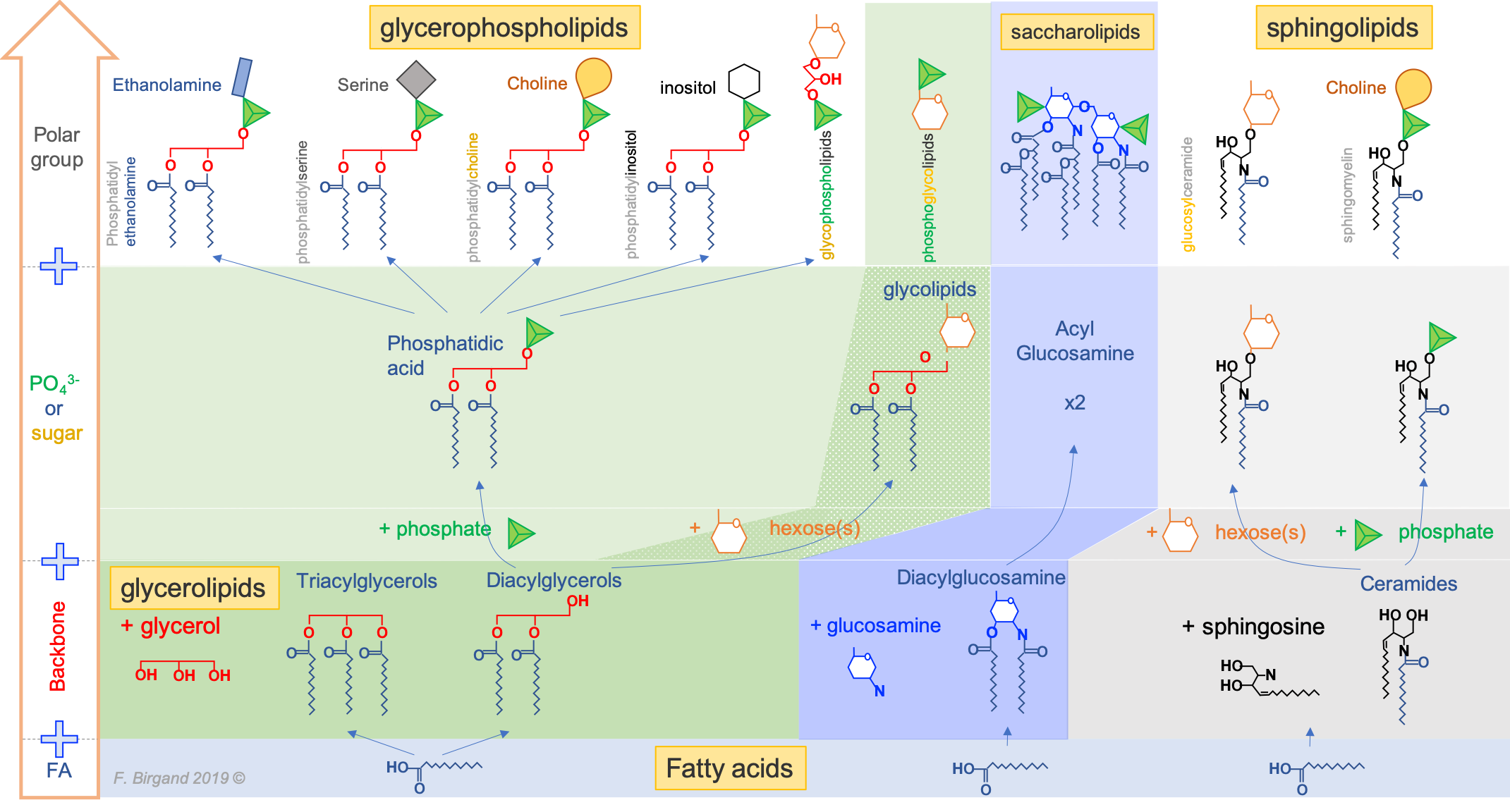
Figure 4.43: The main types of fatty acid based lipids: illustrating the common fatty acid base, and resulting from the three types of backbones and a variety of polar groups making the hydrophilic head)
The second stage molecules are lipids built from fatty acids + a backbone. The backbone molecules can bind with one to three fatty acids on one side, with ester (most often), ether, or amide bonds, and with other radicals on the other side allowing more building blocks to be added. There are three main backbone molecules: glycerol, hexosamine (glucosamine in Figure 4.43), and sphingosine. Mono-, di- and triacylglycerols (previously called mono-, di-, and triglycerides, respectively) play such an important role in metabolism and energy storage, that the glycerolipids have been identified as a group of its own. Glycerolipids with additional building blocks eventually lead to the glycerophospholipid family (green in Figure 4.43). The glucosamine (hexose with an amine group) eventually leads to the saccharolipid family (blue in Figure 4.43). Sphingosine plays both the role of a backbone and of a fatty acid thanks to its long saturated aliphatic tail. Sphingosine-based lipids eventually lead to the sphingolipid family (grey in Figure 4.43).
The third stage are lipid molecules built from fatty acids + a backbone + phosphate or a sugar. It is quite interesting to realize that only two molecules, phosphate or an hexose, play that role. They have enough hydroxy functional group to make ester bonds with other groups. Most glycerophospholipids have a fourth stage of building blocks, and the third stage is thus an intermediate form. Many glycolipids and sphingolipids, however, only have stage three molecules and are incorporated into cell membranes as such.
The fourth stage are lipid molecules with four building blocks: fatty acids + a backbone + phosphate or a sugar + polar group. These molecules make about 50% of the cell membranes and thus play a major role in life. It is the amphipathic nature of these molecules that leads them to readily assemble into acyl lipid bilayers (generally referred to as phospholipids). The hydrophobic tails and hydrophilic heads tend to aggregate together forming a layer or sheet of molecules a bit like a bundle of wheat that would have the stems together and the wheat ears together. Because cells essentially are aqueous systems, the hydrophobic side of the layer is naturally unstable, unless it is stabilized by another layer of phospholipids, with the hydrophobic tails facing each other and the hydrophilic heads facing the aqueous phase of the cell (more details later).
Third and fourth stage acyl-based lipids all have similar features: they have a hydrophobic tail group, and a hydrophyllic head group. As a result, they tend to naturally congregate together to form the famous lipid bilayer in which proteins and glycoproteins, serving as cell receptors, catalyzers, or exchange regulators can readily embed.
In summary:
- Lipids, unlike other molecular families, are not polymers of monomers but are built from building blocks
- Fatty acid long (C16-C22) saturated or unsaturated chains are the basis of what lipids are, sterols being an exception
- Because there are very few oxygen atoms, carbon atoms have more electrons for themselves and lipids thus serve as energy storage for the cell and organisms
- Most membrane lipids are made of two fatty acids forming a hydrophobic tail, linked to a hydrophilic head, thanks to a backbone intermediate molecule
- It is the amphipathic nature of lipids that allow the formation of a bilayer membrane which create cell compartments and in which proteins can be inserted
Time to pause in the strict biochemical description of acyl-based lipids, and spend some time to introduce an overview of the function of these lipids in cell membranes. This should make the description of these be more fascinating later on.
4.5.2 Lipids as key to cell membrane structure and function
In this section, lots of concepts are thrown at the reader, whom might be a bit rebuted by so many apparently complicated names (although most of them already appear in Figure 4.43). I decided to present the membrane function first in hope of making the biochemical description of enough of the lipids more interesting. So no worries, read this as a fascinating introduction to the wonders of life, and of lipids!
The first important concept to grasp is that in the lipid bilayer, the adjacent lipid molecules are not bonded together. It is thanks to their hydrophilic and hydrophobic interactions, and to a lesser degree thanks to electrostatic interactions, that the membrane lipids stay together and that cellular membranes exist altogether. The membrane does not have a solid crystalline nature, but rather a more fluidic nature, where molecules can freely move about within their layer or sheet. Proteins can insert themselves into this bilayer system thanks to the fluidic behavior. They too must have some amphipathic properties as well with hydrophobic and hydrophilic ends. Because proteins are inserted in a mosaic pattern, the fluidic mosaic model proposed in 1972 [Singer and Nicolson (1972); Figure 4.44] was the first accepted model to describe membrane bilayer.
![The **fluidic mosaic model** as published by Singer and Nicholson [-@Singer1972-ng]. The filled circles represent the ionic and polar head groups of the phospholipid molecules, which make contact with water; the wavy lines represent the fatty acid chains which make contact which each other. The membrane is made of **two layers or leaflet of lipids** mirroring each other and touching each other from the fatty acid side. The integral proteins are shown as globular molecules partially embedded in, and partially protruding from, the membrane](pictures/fluidic-mosaic-bilayer-1972.png)
Figure 4.44: The fluidic mosaic model as published by Singer and Nicholson (1972). The filled circles represent the ionic and polar head groups of the phospholipid molecules, which make contact with water; the wavy lines represent the fatty acid chains which make contact which each other. The membrane is made of two layers or leaflet of lipids mirroring each other and touching each other from the fatty acid side. The integral proteins are shown as globular molecules partially embedded in, and partially protruding from, the membrane
The second important concept is that the diversity of membrane lipids and their layout and interactions together allow the concurrent formation of fluidic and more rigid areas in the membrane itself corresponding to different phases. The two main phases are the liquid-disordered phase, very fluidic, almost liquid-like, and the liquid-ordered phase, more gel-like and more rigid.
The liquid disordered phase is a highly fluid state in which individual lipids can move laterally across the surface of the membrane relatively unhindered. Liquid-disordered bilayers are often characterized by irregular packing of individual lipid molecules, as well as the presence of kinks in unsaturated fatty acids. These kinks effectively reduce the surface area accessible to other fatty acid chains, weakening van der Waals interactions (Membrane Phase Transitions, libretext).
When the fatty acid chains are more fully extended because they are more saturated, and/or because they interact with sterols (details below), they become more fully packed and the van der Waals interactions are increased. They yields to a more rigid gel-like structure referred to as the liquid ordered phase. And guess what, this is where the proteins are also located and this makes sense because they have a more rigid structure in which to stay (Figure 4.45).
](pictures/lipid-raft-combined.png)
Figure 4.45: Membranes show a lipidic bilayer structure with lateral heterogeneity. Some lipids associate to form more dense areas known as membrane nanodomains or lipid rafts. In these domains, some proteins are included more frequently by electrochemical affinity. Cholesterol is located among the fatty acid chains, close to hydrophilic heads of the lipids, straighten fatty acids, and provide more rigidity to the membrane. Transmembrane proteins allow communication between extracellular and intracellular environments. Carbohydrates are found in the outer monolayer of the cell membrane forming the so-called glycocalyx. In this figure, the interactions of cell membrane molecules with cytoskeleton and with extracellular matrix are not depicted [Figure and caption after Pacheco Megías, Molist García, and Pombal Diego (2013) and Artur Jan Fijałkowski
In other words, the number of unsaturated bonds in the fatty acid chains have a major impact on how fluidic the membrane is. The more unsaturated, the more kinks, and the more fluidic the membrane. Reversely, the more saturated, the less kinks, the more packed the hydrophobic tails, and the less fluidic the membrane. The addition of sterol lipids tends to generate the more rigid liquid ordered phase (Figure 4.46), and these tend to be present where the proteins are embedded in the membrane (Figure 4.45 and 4.47).
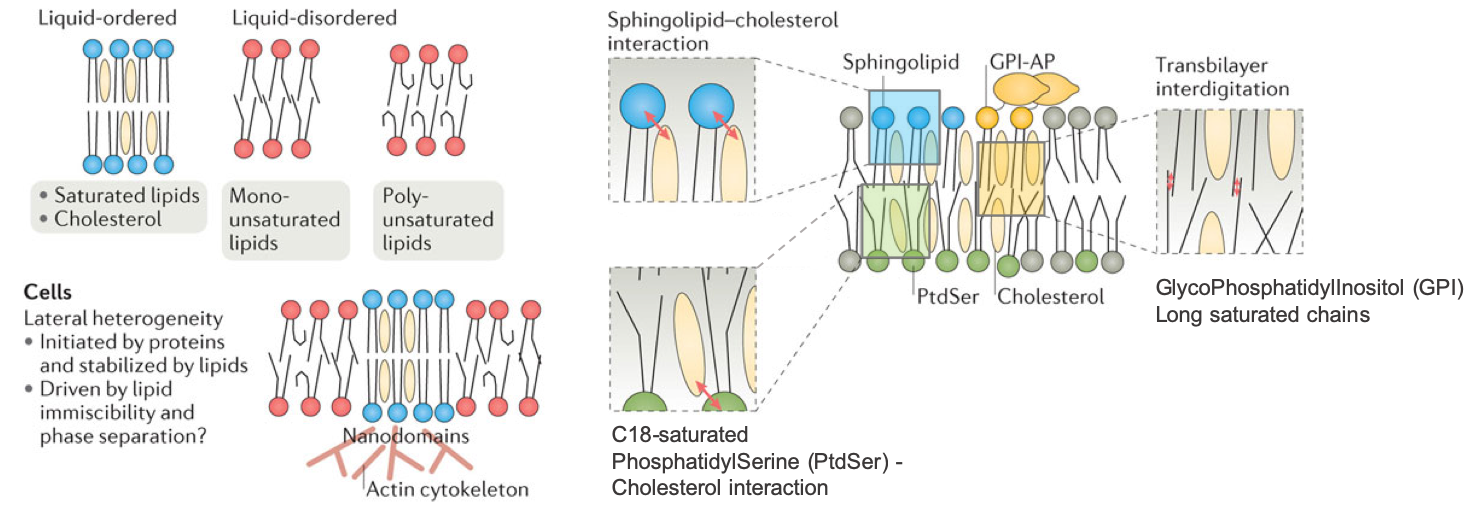
Figure 4.46: Liquid-order and liquid-disorder phases in membranes due to the level of saturation of fatty acids and interactions with cholesterol and transmembrane interactions. AP- anchored protein (after Harayama and Riezman (2018))
The aggregations of lipids around proteins are referred to as membrane rafts (or lipid rafts) or membrane nanodomains (Simons and Ikonen 1997; Edidin 2003) (Figure 4.45 and 4.47). And the lipids that give the liquid-ordered gel-like phase around proteins tend to include sphingolipids and cholesterols (Simons and Ikonen 1997; Ahmed, Brown, and London 1997; Hooper 1999; Varma and Mayor 1998; Edidin 2003; Toulmay and Prinz 2013; Schmidt and Davis 2017; Sezgin et al. 2017; Harayama and Riezman 2018), phosphatidylserine and cholesterol, and phosphatidylinositol, which, thanks to their long aliphatic chains, tend to interact from one leaflet of the membrane to the other (Figure 4.46).
An entire symposium on membrane raft generated this definition which highlights the importance of special lipids and their interactions with cholesterol:
Membrane rafts are small (10–200 nm), heterogeneous, highly dynamic, sterol- and sphingolipid-enriched domains that compartmentalize cellular processes. Small rafts can sometimes be stabilized to form larger platforms through protein-protein and protein-lipid interactions (Pike 2006).
![a | Lipid raft domains are usually defined as small, highly dynamic and transient plasma membrane entities that are enriched in saturated phospholipids, sphingolipids, glycolipids, cholesterol, lipidated proteins and glycosylphosphatidylinositol (GPI)-anchored proteins. Enrichment of these hydrophobic components endows these lipid domains with distinct physical properties; these include increased lipid packing and order, and decreased fluidity. In addition to membrane components, cortical actin plays an active part in domain maintenance and remodelling. Furthermore, membrane lipids are asymmetrically distributed in the inner and outer leaflets, which may further affect membrane organization. b | It is likely that membrane organization is not binary (that is, highly distinct raft and non-raft regions), but instead membranes consist of various raft-like and non-raft domains with distinct compositions and properties. [Figure and caption from @Sezgin2017-zw]](pictures/membrane-Sezgin2017.png)
Figure 4.47: a | Lipid raft domains are usually defined as small, highly dynamic and transient plasma membrane entities that are enriched in saturated phospholipids, sphingolipids, glycolipids, cholesterol, lipidated proteins and glycosylphosphatidylinositol (GPI)-anchored proteins. Enrichment of these hydrophobic components endows these lipid domains with distinct physical properties; these include increased lipid packing and order, and decreased fluidity. In addition to membrane components, cortical actin plays an active part in domain maintenance and remodelling. Furthermore, membrane lipids are asymmetrically distributed in the inner and outer leaflets, which may further affect membrane organization. b | It is likely that membrane organization is not binary (that is, highly distinct raft and non-raft regions), but instead membranes consist of various raft-like and non-raft domains with distinct compositions and properties. (Figure and caption from Sezgin et al. 2017)
Cholesterol, a name that has been used quite a bit until now although not defined, yet, seems to play a major role in membrane rigidity around the membrane nanodomains. It seems that the amide of the sphingolipid backbone can both donate and accept a hydrogen bond, and these hydrogen bonds are within the interfacial region of the membrane, in which the relative paucity of water increases the stability of these bonds (Sezgin et al. (2017); Figure 4.48).
![Cholesterol can create hydrogen bond inside the water free membrane which provides additional rigidity to the membrane in lipid rafts [Figure after @Sezgin2017-zw]](pictures/sphingomyelin-cholesterol-Hbond.png)
Figure 4.48: Cholesterol can create hydrogen bond inside the water free membrane which provides additional rigidity to the membrane in lipid rafts (Figure after Sezgin et al. 2017)
The third important concept is that in addition to lateral heterogeneity around membrane nanodomains, the membrane lipids assemblage dictates the curvature of the membrane and the assemblage is asymetric between the inner and outer leaflets of the membrane (reviewed by Harayama and Riezman (2018); Figure 4.49). The very nature of the membrane lipids leads to a cylindrical shape, a conical shape, or inverted-conical shapes. When assembled together, these shapes allow for membrane curvature and fission (Figure 4.49). Additionally, some membrane lipids such as PhosphatidylSerine (PS), because of the serine (an amino acid) group as the polar group, tends to bind with cytoplasm proteins like actin (considered to be the cytoskeleton, or the skeleton that keeps animal cells together). As a result, PS tends to be on the inner leaflet of the membrane.
Figure 4.49: The shape of the different membrane acyl-based lipids leads to curvature of a membrane leafet, and the overall bilayer membrane results in part from the asymetric layout of the membrane lipids. SM - SphingoMyelin, PC - PhosphatidylCholine, CHOL - Cholesterol, PS - PhosphatidylSerine, PE - PhosphatidylEthanolamine, PE-O - PhosphatidylEthanolamine with ether bonds (after Harayama and Riezman (2018) and Skotland and Sandvig (2019))
The fourth and last important concept is that animal, plant, algal, or bacterial membranes do not have the same membrane lipids. Membrane lipids within an organism may differ from one organelle to the next. For example, the membranes of the thyllakoids, the organelle responsible for photosynthesis, are built with specialized galactolipids. Saccharolipids are found in bacteria only.
It was impossible to leave this section about membranes without providing what is considered a realistic representation of what a membrane might look like in reality. In other words, things are a lot more complex than our brain can fully handle!
![Glimpse at the near future: model of the plasma membrane in full complexity. Featuring: a lipid bilayer composed of hundreds of different lipids, crowded with a large variety of embedded as well as peripherally bonded proteins, a supporting actin skeleton, a cytoplasmic site full of proteins, and realistic gradients of metabolites, ions, and pH [Figure and caption from @Marrink2019-ww]](pictures/membrane-realistic.png)
Figure 4.50: Glimpse at the near future: model of the plasma membrane in full complexity. Featuring: a lipid bilayer composed of hundreds of different lipids, crowded with a large variety of embedded as well as peripherally bonded proteins, a supporting actin skeleton, a cytoplasmic site full of proteins, and realistic gradients of metabolites, ions, and pH (Figure and caption from Marrink et al. 2019)
In summary:
- It is the amphipathic nature of membrane lipids that allows the formation of a bilayer of acyl-based lipids with the hydrophilic heads facing outwards and the hydrophobic tails facing inward
- Because acyl-based lipid molecules in each layer are not bonded together, the lipid molecules can move freely within the sheet
- Proteins are associated with membrane nanodomains where the membrane lipids have a liquid-order or gel-like phase and the membrane is more rigid.
- The membrane nanodomains or lipid rafts are largely enriched in membrane lipids that have straight saturated hydrophobic tails and are enriched with cholesterol
- It is the straight saturated hydrophobic tails of saturated acyls that shorten distances between molecules and increase van der Waals interactions, resulting in a more rigid structure.
- Hydrogen-binding between cholesterol and aliphatic tails add to membrane rigidity in these lipid rafts
- It is the unsaturated bonds in the hydrophobic tail that create kinks in most other membrane lipids, effectively maintaining larger distance between molecules, and weakening the van der Waals interactions, which in the end maintain a liquid-disordered of liquid-like phase of the membrane outside the membrane nanodomains
- The cylindrical or conical shape of the membrane lipids and their lateral placement dictate the curvature and shape of the membrane
- The presence and nature of proteins on the inner or outer side of the membrane is associated with the assymetry of the assemblages of lipids at the inner and outer leaflets of the membrane
- Membrane lipids composition may vary from an organism to another or with organelles within cells
Now that the overview of the functions of membrane lipids is in the reader’s mind, time to enjoy some more detailed biochemistry of lipids!
4.5.3 Fatty acids: lipids of their own and primary common building blocks
4.5.3.1 Saturated and unsaturated fatty-acid chains
So what are fatty acids afterall? Fatty acid are carboxylic acids with a long aliphatic chain (synonymous to long hydrocarbon chain or alkyl chain), which are either saturated (e.g., palmitic acid in Figure 4.51), mono-, or poly-unsaturated (i.e., there are at least one double bond between two consecutive carbon atoms, as illustrated in Figure 4.51; more details in section 3.1.2). The double bond in the aliphatic chain is rigid and can create ‘kinks’ in the 3D shape and their number and locations are key to their final 3D shape. Most fatty acids in nature have even number of carbons and range from 10 to 22 carbon atoms. Most present in membrane lipids have between 16 and 22 carbon atoms.
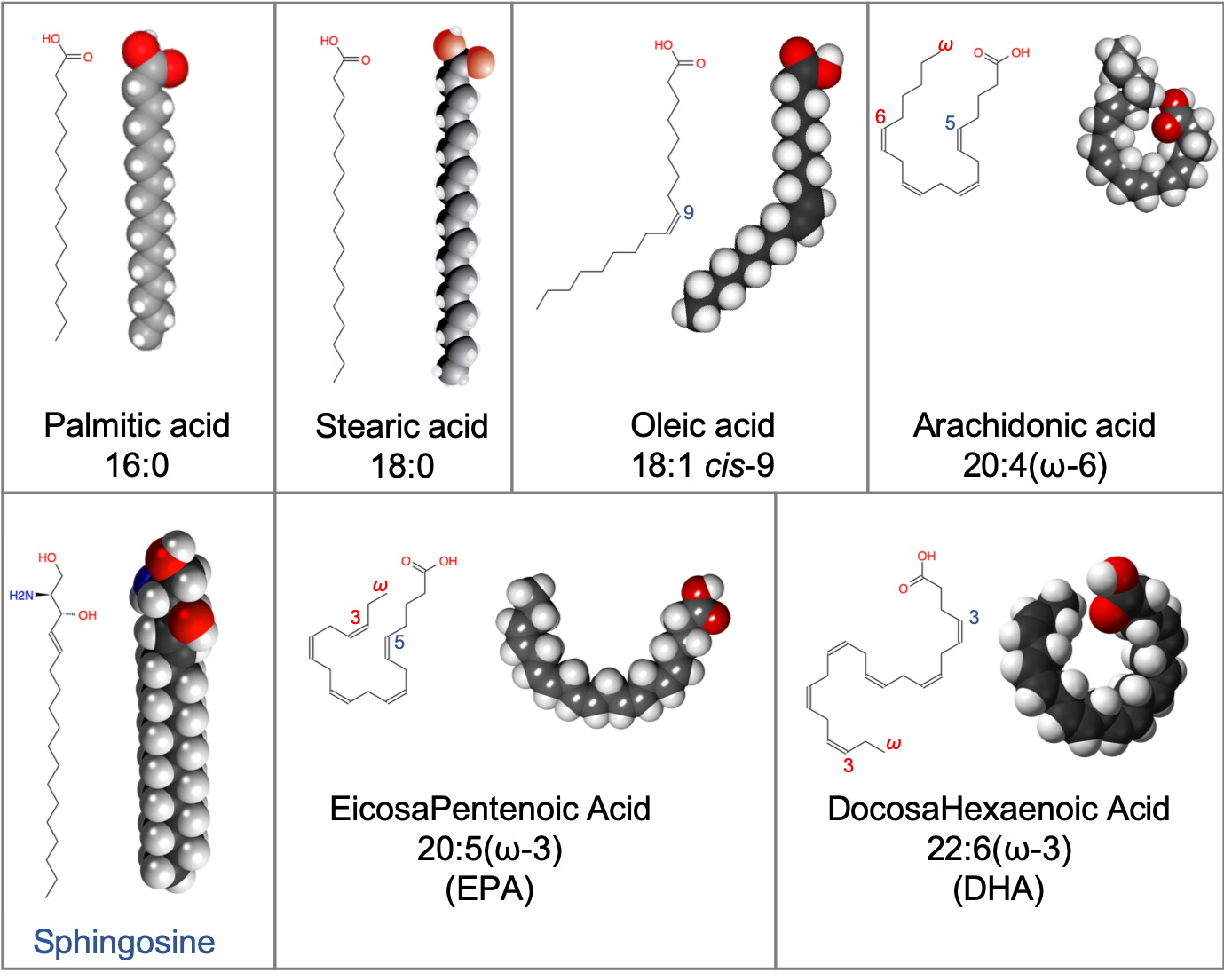
Figure 4.51: Examples of saturated fatty acids (palmitic and stearic acids), mono-unsaturated oleic acid, and poly-unsaturated fatty acids exhibiting ‘kinks’, which when part of a membrane lipids, participate in the fluidic nature of the membrane. Sphingosine technically is not a fatty acid but is illustrated to show that it is straight like a saturated fatty acid. In XX:Y, XX corresponds to the number of carbon atoms, and Y corresponds to the number of unsaturated bonds. ω-3 means that the last unsaturated bond is at 3 carbons from the end (red font). The blue numbers correspond to the carbon number from the carboxyl end. EPA and DHA are abbreviations for these fatty acids. Further explanation in the text below
Fatty acids have been classified according to their carbon-chain length and their level of saturation.
According to their length,
- Short-chain fatty acid (SCFA) have aliphatic chains with less than 6 carbon atoms. Even acetic acid (CH2COOH, acid of the vinegar) is classified in this category; so is butyric acid (C4)
 present in butter.
present in butter. - Medium-chain fatty acids (MCFA) are fatty acids with aliphatic tails of 6 to 12 carbons, which can form medium-chain triglycerides.
- Long-chain fatty acids (LCFA) are fatty acids with aliphatic tails of 13 to 21 carbons. These are the typical molecules to which the generic term is often associated.
- Very long chain fatty acids (VLCFA) are fatty acids with 22 or more carbons. VLCFA can represent up to a few percent of the total fatty acid content of a cell.
Fatty acids are then classified depending on whether they are saturated, mono- or polysaturated, but also whether there are some methyl, cyclic, hydroxy, or nitro radicals in their chains, to name a few. This is way beyond the purpose of this book but many details can be found on the LipidWeb maintained by Dr. Christie or classified by Fahy (2005, 2009).
In addition to being precursors of other lipids, fatty acids have their own metabolic role. For humans, many fatty acids play essential roles in, e.g., brain activities, cellular messengers, or have been identified to have health benefits. Two fatty acids are considered essential fatty acids for humans, i.e., that humans need them but lack the ability to synthesize them (Figure 4.52).
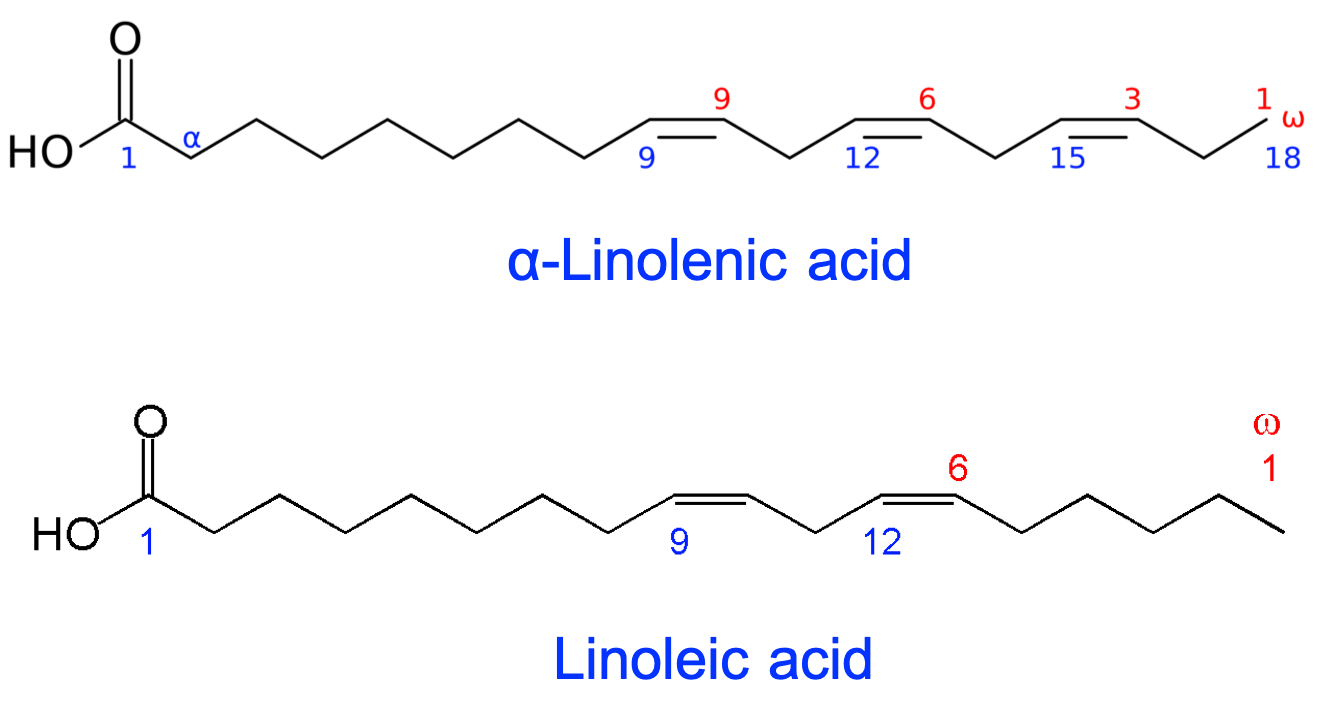
Figure 4.52: α-linolenic acid (omega-3 acid) and linoleic acids (omega-6 fatty acid) are the two essential polyunsaturated fatty acids humans must ingest for their metabolic needs
4.5.3.2 The famous omega-3 and omega-6 fatty acids
The Alpha Linoleic Acid (ALA) is an omega-3 fatty acid. This very common everyday life denomination gives the opportunity to introduce some nomenclature and fascinating facets of fatty acids. As stated before, in organic chemistry in general, each carbon is given a number, carbon number 1 starting with the most important functional group. As a result, in fatty acids, the carbon of the carboxyl group is given the value “1” (blue numbers in Figures 4.51 and 4.52). In unsaturated fatty acids, the number and location of the double bond(s) are very important because, again, it influences the 3D shape of the aliphatic chains (Figure 4.51) and is reflected in the naming.
So the first approach to name fatty acid is to follow organic chemistry rules. For example, linoleic acid is a 18 carbon molecule and has two unsaturated bonds. The corresponding alkane is an octadecane, octadec- prefix meaning 18. But it also is a carboxylic acid, so the suffix will be -oic. It has two unsaturated bonds, so it is a diene, di- for 2, and -ene for alkene. The placement of the unsaturated bonds are on the 9th and 12th carbon. So its name is a 9,12-octadecdienoic acid or octadec-9,12-dienoic acid!! OK, but this does not really explain the omega part.
In molecules of 16 to 22 carbons, it became obvious to chemists that it was just as easy to count from the other end or methyl end (fewer carbons to count!) to locate the double bonds. So they started to also report counting from the methyl end. Since “the alpha and the omega” is a known biblical expression meaning “the beginning and the end”, the “alpha” of the fatty acid became the beginning of the aliphatic chain (i.e., carbon number 2, see α linolenic acid in Figure 4.52), and the “omega” became the end carbon of the aliphatic chain. The expression “omega-3” really means “omega minus 3”, or that the last unsaturated bond is located at three carbons from the end.
But what about the other double bond(s)? How does one know where it is (they are) located? Well, it turns out that for most polyunsaturated fatty acids, the double bonds are located every 3 carbons! Such that the carbons on each side of the double bonds are in the cis configuration, or that they ‘face’ each other rather than being on the oposite side of the double bond (in which case they would be in a trans configuration, further description in section 3.1.2). So lipid chemists have come up with much simplified nomenclature and the linoleic acid would then be referred to as a 18:2(n-3). This means that the fatty acid has 18 carbons, has 2 unsaturated bonds, the last one is the third carbon from the end (n-3, n replaces ω in most modern naming). And because there are no further precisions, all the double bonds are in a cis configuration and therefore the other double bond is at an (n-6) location. Voilà!
The omega-3 fatty acids are a gateway to health sciences and medicine! Briefly, the two essential fatty acids cited above serve as precursor to other very important fatty acids. The first notable one is the arachidonic acid (20:4(n-6)). The name arachidonic acid suggests that this acid is particularly present in peanut oil. You should now be able to write its formula before you check it out and verify it from Figure 4.51! Arachidonic acid is the preponderant fatty acid included in the membrane phospholipids. It is also the presursor of very important C20 and C22 fatty acids, building blocks of membrane phospholipids of the brain. In fact, there is high probability that you might have heard about the EPA (eicosapentenoic acid 20:5(n-3), eicos- meaning 20, -penten- meaning five double bonds), and DHA (docosahexaenoic acid 22:6(n-3); docos- meaning 22, -hexaen- meaning six double bonds). With ALA, EPA and DHA are the most talked and researched after omega-3 lipids!! And indeed, there are lots of evidence that these omega-3 are good for human health (e.g., Kris-Etherton, Hecker, and Binkoski 2004). Many conjugated (i.e., alternating single and double bonds; double bonds in trans configuration) polyunsaturated fatty acids have also recently been reported to have health benefits (e.g., Pariza, Park, and Cook 2000; Kris-Etherton, Hecker, and Binkoski 2004; Benjamin and Spener 2009) .
Because arachidonic acid is so widely needed and available, it is also the precursor of an entire family of fatty acid derivatives referred to as the eicosanoid lipids (eicos- meaning 20, -oid meaning “like” or “derivatives”). These are oxidated fatty acids (then referred to as oxylipins) that serve as cellular messengers in mammalians. Their names might be familiar and include prostaglandins (vasodilators) or thromboxanes (vasoconstrictors).
In summary:
- Fatty acids are carboxylic acids so technically even acetic acid (C2) or butyric acid (C4, in butter) are fatty acids.
- Their hydrophobicity comes from their relative long aliphatic chains (C10 and up)
- Saturated fatty acids have straight aliphatic chains and take little 3D space
- The number and placement of unsaturated (C=C) bonds dictates their 3D shapes from a simple kink like in oleic acid to almost snail like shape for DHA
- When a moeity of membrane acyl-based lipids, the nature and therefore shape of the fatty acids dictates the fluidity or rigidity of the membrane
4.5.4 Glycerolipids for energy storage
Nearly all the commercially important fats and oils of animal and plant origin consist almost exclusively (>95%) of the simple lipid class - triacylglycerols, which are chemically inert, highly hydrophobic and have a high energy density. This includes all the vegetable oils, such as those from corn (maize), olive, palm, and sunflower, and animal fats, such as tallow, lard and butter, as well as commercial products such as margarines (W. (bill). W. Christie, n.d.).
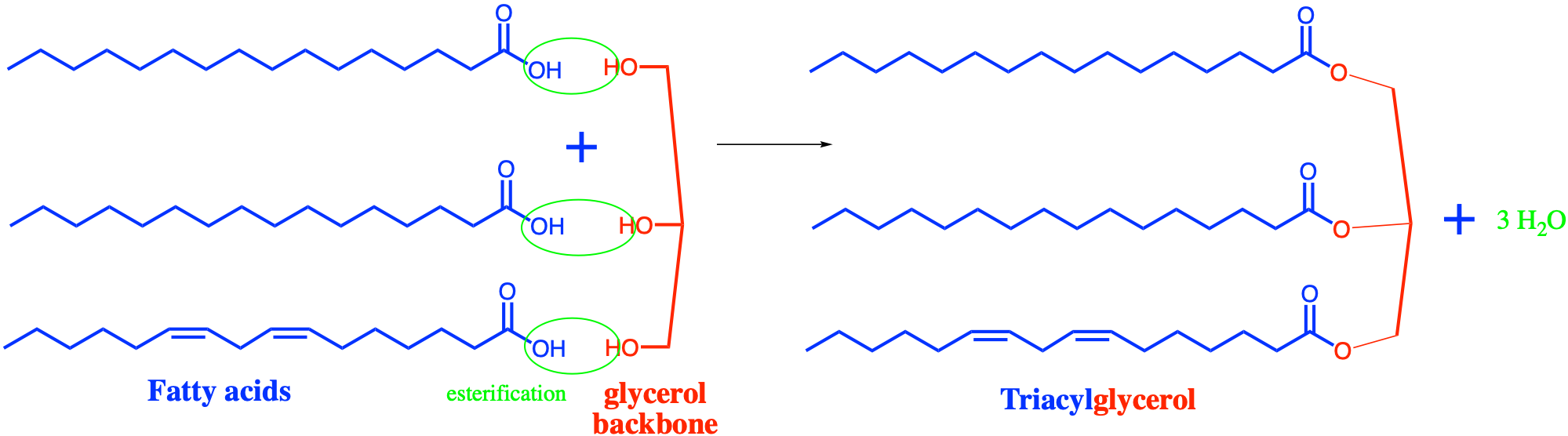
Figure 4.53: Formation of triacylglycerols by esterification of three fatty acids to a glycerol backbone
Triacylglycerols are the quintessential model for the fat lipids (e.g., Figure 4.40). They are assemblages of long chain fatty acids esterified to a glycerol backbone (Figure 4.53). Fatty acids very loosely represent the equivalent of monomers in lipids, but the ester bonds do not represent true polymerization as the fatty acids are not directly bonded together, but are bonded to a backbone instead.
Glycerolipids give the opportunity to reintroduce the term moiety. In a triacylglycerol, the glycerol moiety refers to as the part of the triacylglycerol that comes from the glycerol, illustrated in red in Figure 4.53. Lipids and nucleic acid monomers are assemblages of recognizable building blocks and each block in the final molecule is referred to as a moiety. The other moieties of triacylglycerol are the fatty acids.
There is an entire classification of triacylglycerols depending on which glycerol atom is bonded to which fatty acid. But that is beyond what is needed here. The word triacylglycerol has been preferred over the older triglycerides.
The equivalent of glycerolipids for the sugar backbone and sphingosine are covered in the sections below dedicated to saccharolipids and sphingolipids, respectively.
4.5.5 Glycerophospholipids or phospholipids for cell membranes
4.5.5.1 Phosphatidic acids as first type of third stage molecules
The next stage of building blocks after the glycerolipids is the addition of a phosphate moiety to a diacylglycerol via a phosphoester bond with the remaining hydroxy group of the glycerol moiety (Figure 4.54) to form phosphatidic acid. This molecule is an intermediate molecule for the synthesis of glycerophospholipids, built from the addition of, a least, another polar group building block.
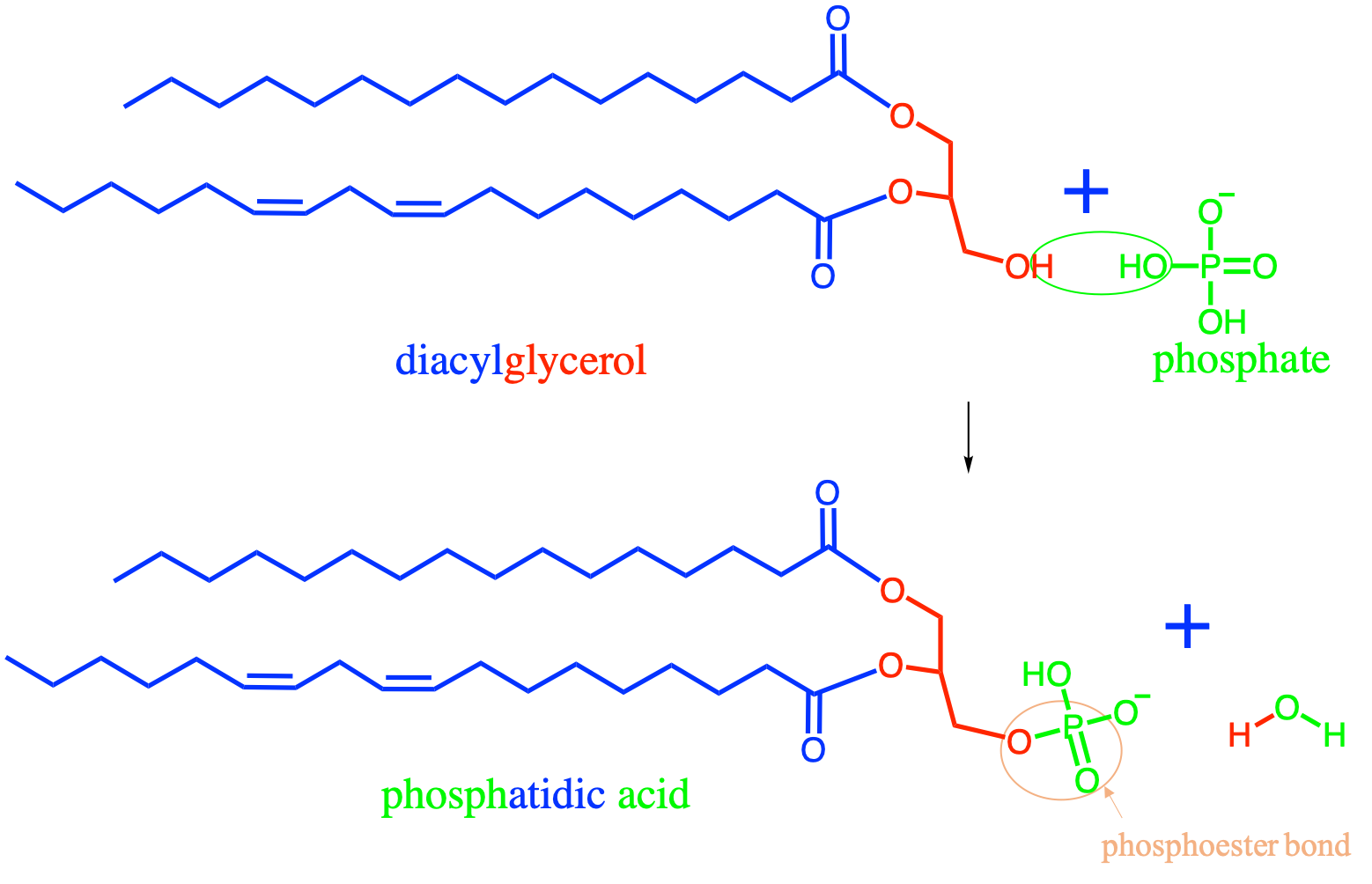
Figure 4.54: Formation of phosphatidic acid by esterification between a diacylglycerol and a phosphate
Notice that because phosphoric acid has three hydroxy groups, it can theoretically make up to 3 ester bonds. In reality, this does not happen in organic molecules for several reasons. First, the tetrahedral shape of phosphate renders difficult the possibility of binding three aliphatic chains. Second, the electronic resonance makes the third hydroxy much less attractive to forming bonds when the two others are already involved in bonds. So, for the vast majority of cases, phosphates can only form up to two phosphoester bonds.
Phosphatidic acid has two hydroxys available for additional binding, and one of them is used to bind with the fourth stage building blocks constituted by polar groups. The phosphatidic acid becomes a substituent to the polar group and the resulting molecules are then referred to as phosphatidyl polar group name. These are the famous phospholipids that make the majority of the membrane bilayer of most plants, animals and bacteria. Another group called the glycolipids have a sugar instead of a phosphate moiety on the third stage. They are treated separately after the four stage phospholipid molecules below.
4.5.5.2 The main membrane phospholipids
The quintessential phospholipid is illustrated in Figure 4.42 and is the single unit of the membrane bilayer. Again, it is thanks to its hydrophobic double tail and its hydrophylic head that the phospholipids assemble into phospholipid sheets and into phospholipid bilayers. Two of the glycerol backbone carbons are linked to fatty acids, and the third to the phosphate moeity. There are three theoretical possibilities for this assemblage. In reality, it turns out that the placement of the fatty acyl and the phosphate ester bonds on the glycerol backbone is anything but random.
Chemists have thus given stereospecific numbering or sn to represent this fact. The word stereospecific has to do with the 3D configuration as rendered by the Fisher projection of the glycerol. But for us, the important fact is that the carbons of the glycerol are numbered and that the phosphate moeity is always bonded to the third carbon or is on sn-3. The only exception is the lysobisphosphatidic acid, where the phosphate moiety is on sn-1 (W. (bill). W. Christie, n.d.).
Interestingly, on the first carbon of the glycerol, or on sn-1 the fatty acyl is most often saturated, and it is on the second carbon, or sn-2 that unsaturated fatty acyls may be found. This is why in all the previous figures that represented phospholipids with a bead for the hydrophilic head and lines for the tails, there always is one of the tails represented as straight, illustrating the saturated fatty acyl on sn-1 and the second tail is either straight or kinked representing the saturated or unsaturated fatty acyl, respectively, on sn-2.
The diversity of phospholipids results primarily from the different assemblages of the fatty acyl on sn-1 and sn-2, and on the polar group of the hydrophilic head. There are additional phospholipids that do not strictly follow this 4-stage molecular assemblage (details below). It turns out that although there is an almost infinite number of possible combinations, in practice, some polar groups combine with a limited number of saturated and unsaturated acyl groups.
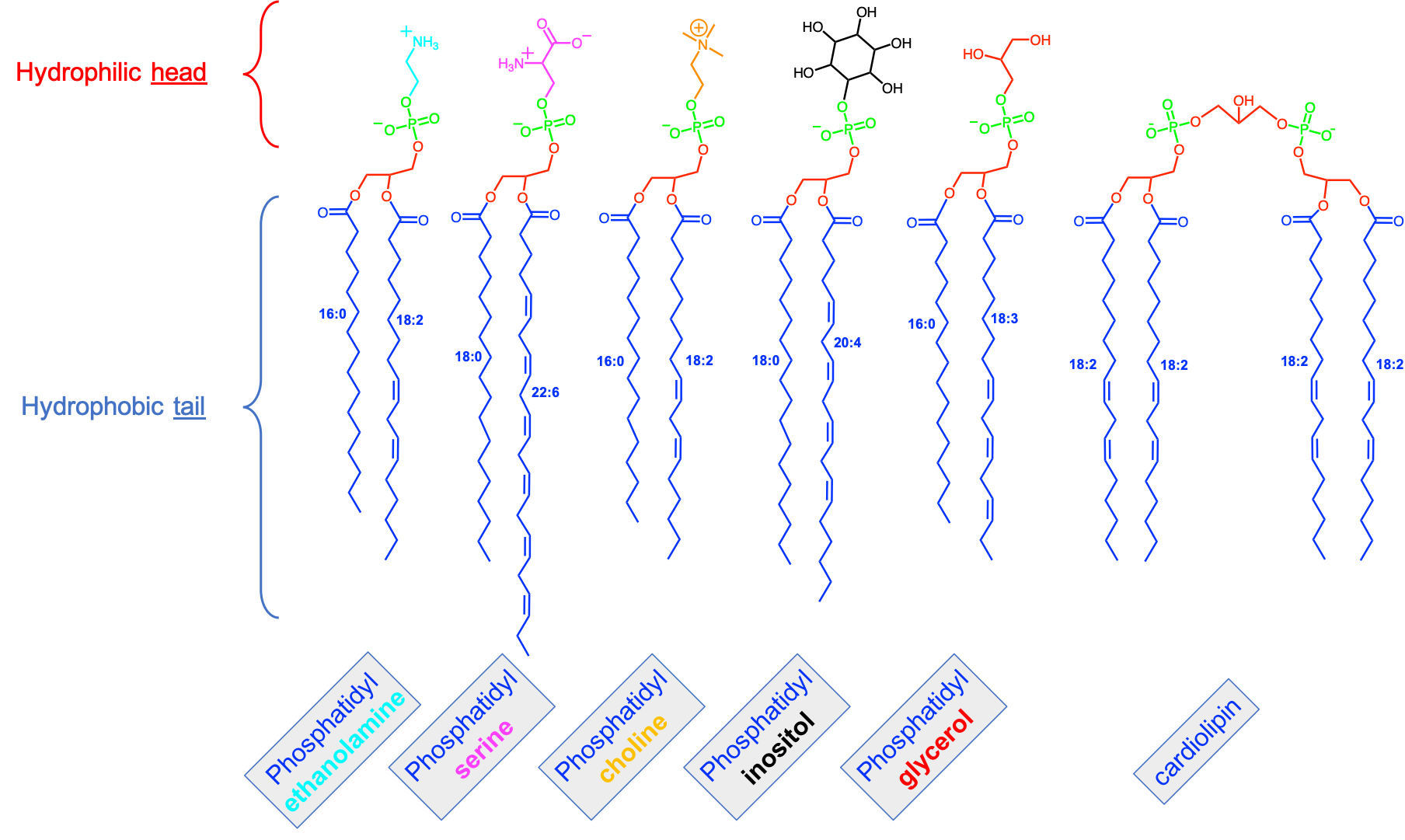
Figure 4.55: Variety of phospholipids showing the five most common polar groups and fatty acyls that tend to be preponderant for each of the polar groups. The fatty acyls on sn-1 is represented as saturated as is most often the case, and the unsaturated fatty acyls on sn-2 are represented as straight aliphatic chains although there are not in reality
Among the 4-stage phopsholipids, there are five well identified polar groups, which include ethanolamine, serine, choline, inositol, and glycerol. Because each of these polar groups are bonded to phosphatidic acid via a phosphoester bond, they are called, respectively, phosphatidylethanolamine (PtdE), phosphatidylserine (PtdSer), phosphatidylcholine (PtdChl), phosphatidylinositol (PtdIno), and phosphatidylglycerol (Figure 4.55).
Phosphatidylcholine (PtdChl) is the most abundant lipid in the membranes of animal tissues; it is often a major lipid component of plant membranes, but only rarely of bacteria. With the other choline-containing phospholipid, sphingomyelin, it is a key structural component and constitutes much of the lipid in the external monolayer of the plasma membrane of animal cells especially (W. (bill). W. Christie, n.d.). Choline is an ethanolamine (see below) for which the amine group is in its cationic from (i.e., -NH3+) and where the hydrogens have been replaced by methyl groups to create (-N(CH3)3+). The positive charge on the nitrogen is compensated by the negative charge on the phosphate, making PtdChl a neutral phospholipid. The fatty acids on sn-1 tend to be 16:0 and 18:0 for both animal and plant cells, and 18:1 and 18:2 on sn-2 (W. (bill). W. Christie, n.d.), so relatively small number of unsaturated bonds compared to other phospholipids. PtdChl is rarely being found in bacteria, although it is often the main complex lipid in eukaryotes (W. (bill). W. Christie, n.d.).
Phosphatidylethanolamine (PtdE) is usually the second most abundant phospholipid class in animal and plant tissues, and it can be the major lipid class in microorganisms (W. (bill). W. Christie, n.d.). Ethanolamine corresponds to an ethane or C2 with one hydroxy group (-OH) on one carbon making ethanol, and an amine group (-NH2) on the second carbon; the two combined is called ethanolamine. It is bonded to the phosphate via a phosphoester bond. The amine group in PtdE tends to be in its cationic form, making PtdE also a neutral phospholipid. The fatty acids tend to mimic those of PtdChl although there is a higher proportion of polyunsaturated (e.g., 20:4) acyls on sn-2 for animal cells. PtdE is often the most abundant lipid class in many bacterial species and may be accompanied by phosphatidylserine and phosphatidylglycerol (W. (bill). W. Christie, n.d.).
Phosphatidylserine (PtdSer) is a weakly acidic lipid that is present in most tissues of animals and plants and is also found in microorganisms. Under normal conditions, it is located entirely in the inner monolayer leaflet of the plasma membrane and other cellular membranes (W. (bill). W. Christie, n.d.). Serine is an amino-acid (details in section 4.3) and tends to readily bind to proteins within and outside the membrane with cytoplasmic proteins such as actins making the cytoskeleton of animal cells. The fatty acids on sn-1 tend to be 18:0 for animal cells, and be long polyunsaturated 20:4 and 22:6 on sn-2 (W. (bill). W. Christie, n.d.), so relatively high number of unsaturated bonds compared to other phospholipids.
Phosphatidylinositol (PtdIno) is a common constituent of animal, plant and microbial lipids. Inositol is an interesting carbohydrate: it is a cyclohexane, for which each carbon has been oxidized and lost a hydrogen for a hydroxy (-OH). So it has six alcohol groups or is an hexol, with the same general formula as glucose, i.e. C6H12O6. Glucose has an aldehyde group on its 6th carbon and is thus different. In animal tissues, the characteristic feature of fatty acids is a high content of stearic (18:0) and arachidonic (20:4) acids. The long tails of arachidonic acids from PtdIno on both sides of the membrane seems to be able to form hydrogen bonds, participating in the liquid-ordered phase of membranes (e.g., Figure 4.46). The hydroxy groups of inositol react with phosphate to from inositol mono-, bi- or even tri-phosphates, all of which PtdIno play, in animal cells, important signalling and other functional activities, including cell communication via signal transduction, cell survival and proliferation, membrane trafficking and modulation of gene expression (W. (bill). W. Christie, n.d.). Phosphatidylinositols also serve as anchors to proteins (see protein anchor in Figure 4.45) in animal cells.
While the previous phospholipids are common in eukaryot cells, bacterial cells tend to have different types and proportions of phospholipids.
Phosphatidylglycerol is a lipid present in the three kingdoms of life although it is a major component of some bacterial membranes. The charge on the phosphate group means that it is an anionic lipid at neutral pH with a larger head group than might be expected because of hydration and with a cylindrical shape overall.
Phosphatidylglycerol is found in almost all anaerobic bacterial types, representing 20-25% of the phospholipids in most Gram-negative bacteria, i.e. with a double (outer and inner) phospholipid envelope, where it is present only in the inner membrane. In Gram-positive bacteria, which have a single phospholipid bilayer coated with peptidoglycans, it can be as high as 60% of the phospholipids (together with glycosyl diacylglycerols). In cyanobacteria and plants that are able to carry out aerobic photosynthesis, phosphatidylglycerol is found in all cellular membranes - 2 to 5% of the plasma membrane. In bacteria, phosphatidylglycerol especially is widely distributed and it is found in most genera; uniquely it is the only glycerophospholipid in the membranes of certain cyanobacteria (W. (bill). W. Christie, n.d.).
The last of the phospholipids presented here is cardiolipin, which was originally found in animal heart tissue (Figure 4.55). It can be seen as the condensation of two phosphatidylglycerol molecules into one. Cardiolipin is present universally in both prokaryotes and eukaryotes where it represents an important phospholipid component of specific membranes in those organelles whose function is to generate an electrochemical potential for substrate transport and ATP synthesis. Thus, it is found almost exclusively in certain membranes of bacteria (plasma membrane and hydrogenosomes) and a few species of Archaea (haloarchaea), and in mitochondria of eukaryotes (up to 20% of phospholipids) (W. (bill). W. Christie, n.d.). This phospholipid is rather negative thanks to the two negative charges of the phosphate, which may explain its role in maintaining electrochemical potentials across the membranes (see Chapter 5).
There are other phospholipids described in exhaustive classifications, but this is beyond the scope of this book. Additional references include the LipidWeb, Fahy et al. (2005) and Fahy et al. (2009) as good starters.
Phospholipids by definition involve phosphate as a central moiety between the backbone and the polar group. This is one of the reasons for which phosphorus and phosphate in particular are so essential for life to exist on this planet. However, we will see that phosphorus in reality is not readily available in many areas of our planet and this is why it has historically been a limiting nutrient on our planet for the longest time. This has recently changed (since the late 1950s) thanks to the mining and manufacturing of artificial fertilizers. However, because phosphorus was in so short supply, organisms have found ways to still build their membranes using the building block principle, but without using phosphate, and using hexoses instead.
4.5.5.3 Glycosyldiacylglycerols or where phosphates are replaced by sugars
The title is a bit of a mouthful, one has to admit… But the idea here is that instead of a phosphate in phosphatidic acid, the diacylglycerol moiety is bonded to a sugar via a glycosidic bond. The sugar moeity, because it is linked via this glycosidic bond is called a glycosyl group, hence the name (Figure 4.56). Sugars have multiple hydroxides hence possibilities to make bonds with other hydroxides, and in this case with the last hydroxide available on the glycerol backbone of diacylglycerols.
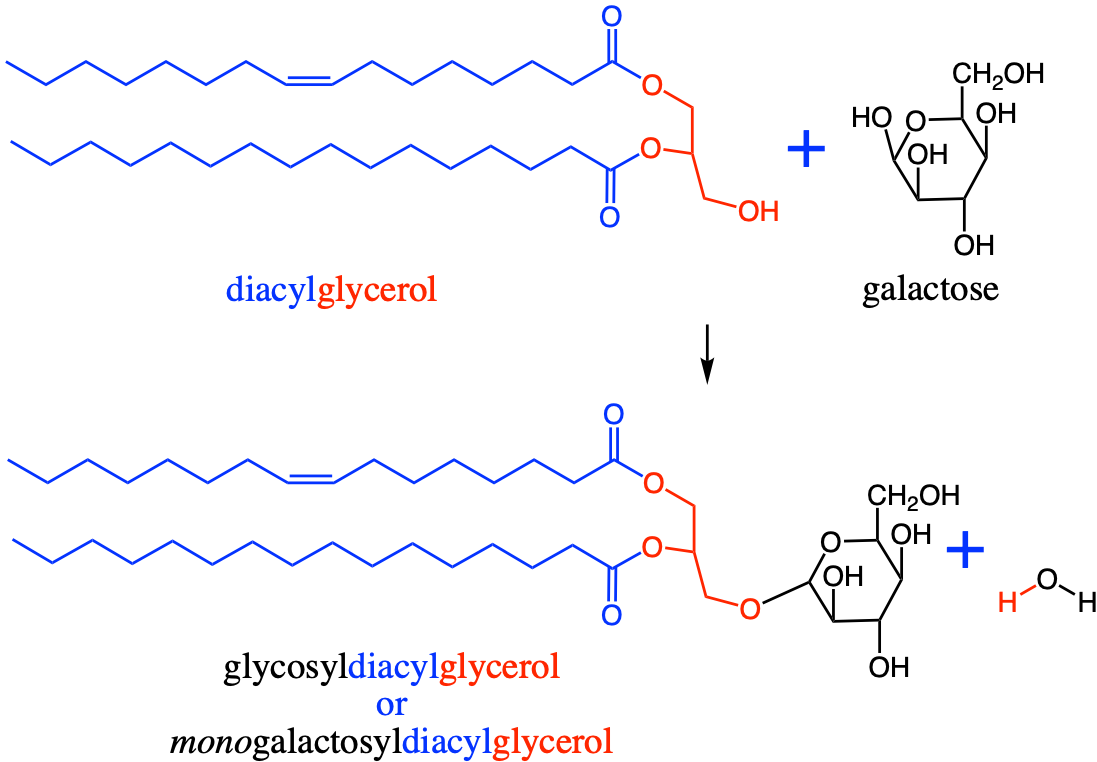
Figure 4.56: Formation of a glycosyldiacylglycerol by binding a galactose to a diacylglycerol moiety using a glycosidic bond to form the majority of the innerside of the membrane lipids of thylakoids in chloroplasts and cyanobacteria
The sugars acting as backbones are galactose or digalactose (two galactoses bonded by a glycosidic bond), but also a sulfoquinovose presented in the carbohydrate section and glucuronic acid (W. (bill). W. Christie, n.d.). The three glycolipids illustrated in Figure 4.57 are the membrane lipids essential to photosynthetic tissues in both higher plants and cyanobacteria. In fact these three account for more than 85% of the membrane lipids in thylakoids of plant plastids and cyanobacteria (Kobayashi 2016). These glycoglycerolipids are equivalent to and may substitute for phosphoglycerolipids, especially when the supply of phosphorus is restricted (Essigmann et al. 1998; Güler et al. 1996). In fact, these glycolipids are the most abundant lipid classes in leaf (photosynthetic) tissues (W. (bill). W. Christie, n.d.).
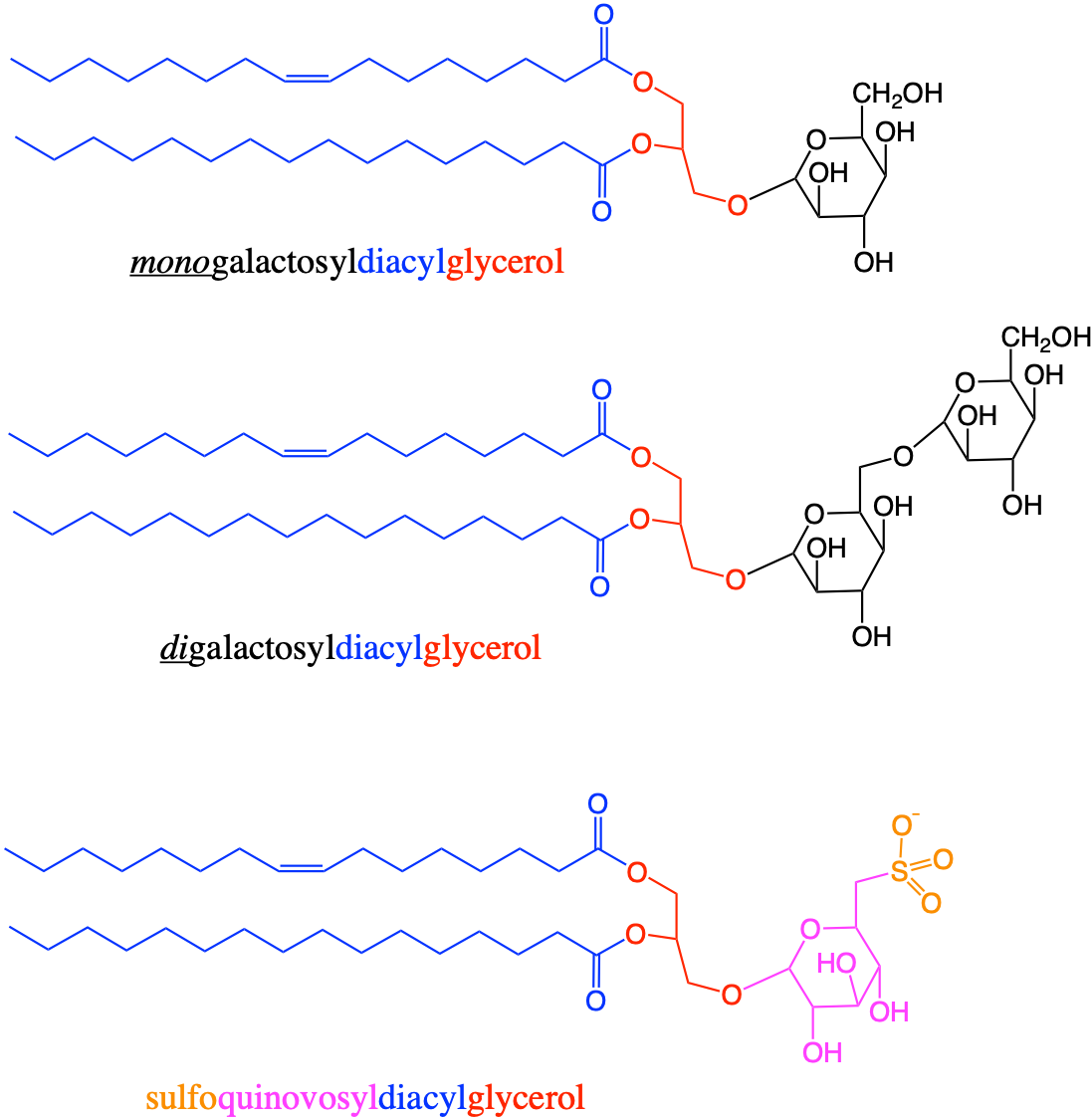
Figure 4.57: Three main glycolipids that make the majority of the innerside of the membrane lipids of thylakoids in chloroplasts and cyanobacteria
In summary:
- Phospholipids are the core molecules that form membranes that allow compartmentalization in cells essential to life as they regulate exchanges and allow formation of gradients
- This is possible thanks to the unique assemblage of two long chain fatty acids on a glycerol backbone forming the hydrophobic side, and on the other side, a phosphate and a polar group resulting in a hydrophilic side
- The overall charge of the phospholipids depend on whether the negative charge of the phosphate is balanced or not by the charge of the positive charge of the polar group.
- Phosphatidylcholine is the most common phospholipid in eukaryot and prokaryot cells. Some organelles and cells can contain high proportion of specific phopholipids like the cardiolipin in organelles maintaining electrochemical potentials across the membrane
- There is a relative correlation between the fatty acid types and the polar groups
- Phosphate limited environments have lead certain bacteria and cyanobacteria to develop fatty acylglycerol-based membrane lipids that use sugars instead of phosphates
4.5.6 Sphingolipids use sphingosine as backbone/fatty acid
The second major type of acyl-based lipids are called sphingolipids. From their original discovery from brain cells in the 1880s to modern times, sphingolipids have shown some enigmatic traits (Thudichum 1884; Merrill et al. 1997; Spiegel and Milstien 2003). The original building block is sphingosine (C18). This molecule originally discovered in brain has many of the traits of saturated fatty acids because of its long saturated aliphatic chain, yielding the same hydrophobic properties of fatty acid tails. Carbons 1 and 3 are oxydized into alcohol groups, carbon 2 has an amine group, while there is a double bond between carbons 4 and 5 (Figure 4.58). The amine group can react with the carboxyl group of a fatty acid to form an amide bond, to form ceramide, which is the equivalent of diacylglycerol or second stage molecules described above. The prefix cer- in ceramide has its roots in the word cerebral, for brain, following the early discoveries. The amide bond is rather rigid thanks to the partial double bond between the amine and the carbonyl functional groups (details in section 3.2.12), which reduces the aliphatic chain fluctuations. This with the added rigidity thanks to cholesterol molecules (details in section 4.5.11 below), shortens the intermolecular distances between sphingomyelin molecules and facilitates the formation of hydrogen bonds between them thereby promoting the formation of a hydrogen bond network and a stable ordered phase (W. (bill). W. Christie, n.d.). The hydroxy group on carbon 1 can bind with polar groups such as phosphocholine or phosphoethanolamine, or sugars (Figure 4.58).
As a result, sphingosine serves as a backbone because it can bind with a fatty acid on the hydrophobic tail end and with a polar group to form a hydrophilic head. Sphingosine also plays the role of a second fatty acid thanks to its hydrophobic saturated tail. Sphingosine is the most prevalent of the many (over one hundred!) sphingoid bases that have been identified, which differ depending on the number of carbons, whether there are two (or d- for di-) or three (or t- for tri-) hydroxy groups, and whether there is, and the location of, a unsaturated C=C double bond, to keep it short. Sphingosine has its unsaturated bond between carbons 4 and 5, and in the trans or E (for German Entgegen) configuration (details in section 3.1.2). Sphingosine is thus abbreviated as 4E-d18:1, meaning 4E for unsaturated bond starting on carbon 4 with the Entgegen configuration, d because there are two hydroxys on C1 and C3 (the amine group is always on C2 in sphingoid bases), 18:1 for a C18 aliphatic chain overall and one unsaturated bond. For example, bases include dihydrosphingosine which is a d18:1, phytosphingosine which is a t18:1, and dehydrophytosphingosine which is a 7E-t18:1 (W. (bill). W. Christie, n.d.).
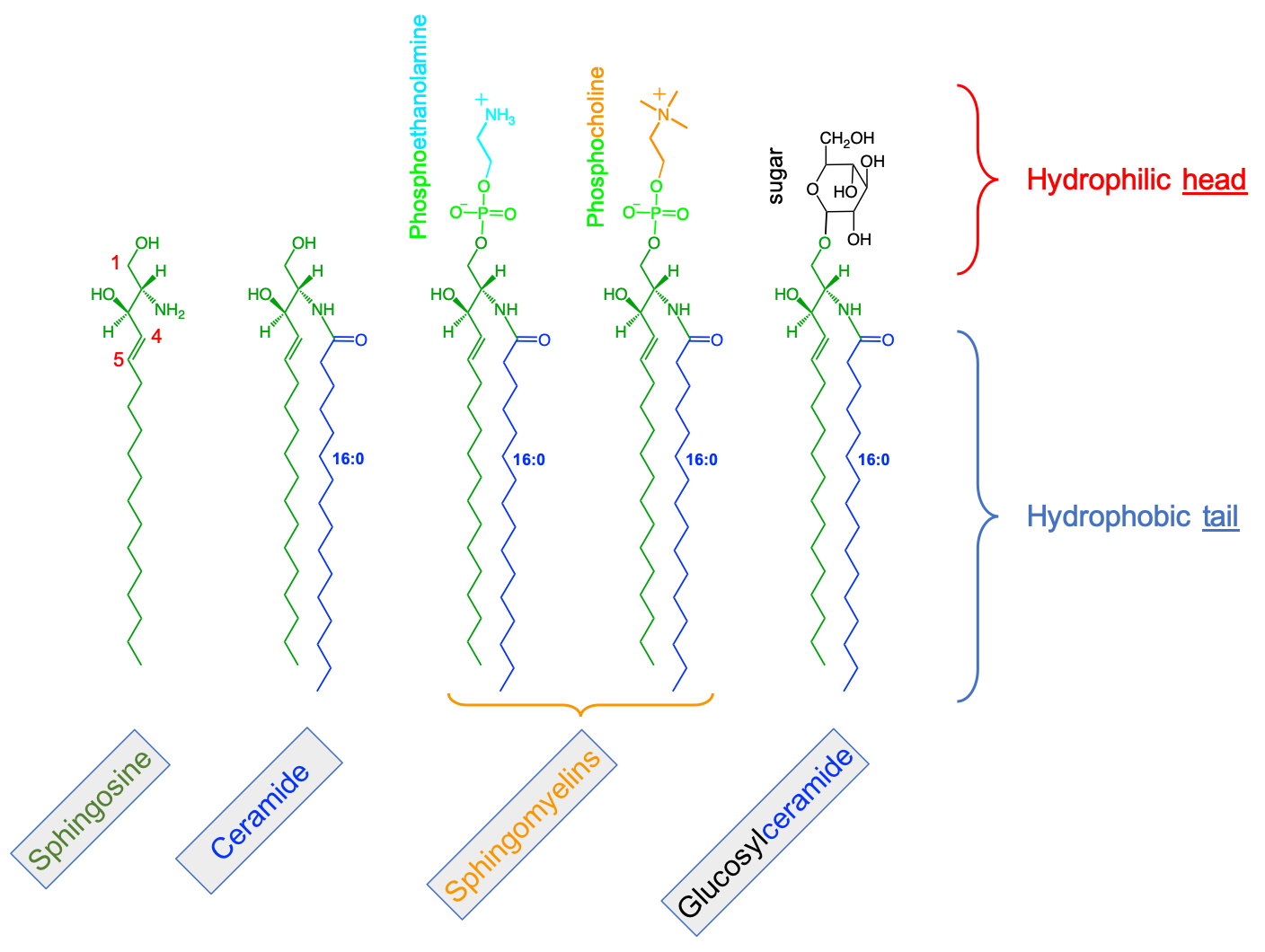
Figure 4.58: Illustration of sphingolipids and their building blocks. A fatty acid added to sphingosine, forms ceramide. Addition of phosphoethanolamine and phosphocholine polar groups form sphingomyelins, or the addition of sugar(s) form glycosphingolipids (or glucosylceramides)
Many polar groups have been identified for sphingolipids including phosphocholine or phosphoethanolamine, for which the resulting lipids are called sphingomyelins. Sugar based polar groups form a great variety of molecules referred to as glycosphingolipids that are very important in brain tissues.
More generally, however, sphingolipids play a very important role in the membrane nanodomains, where in conjuction with cholesterol, form the liquid-ordered, gel-like phase, membrane proteins are inserted (details in section 4.5.2). The fatty acids of sphingolipids are very different from those of glycerolipids, consisting of very-long-chain (up to C26) odd- and even-numbered saturated or monoenoic (W. (bill). W. Christie, n.d.). This additionally renders the ceramide residue to have a cylindrical shape (Figure 4.51), which, in conjunction with hydrogen bonding between cholesterol and the sphingoid base residues, increase the van der Waals electrostatic forces, and favor the liquid-ordered phase of the membrane nanodomains. Finally, sphingolipids play an important, yet still relatively enigmatic, signalling function in animal organisms (Spiegel and Milstien 2003).
Etymology Corner
The prefix sphingos- in sphingosin or in sphingolipids is the genitive of sphinx in Greek. In Greek mythology, the sphinx is a female monster with the body of a lion, the head and breast of a woman, eagle’s wings, and a serpent’s tail. She dwelt outside the city of Thebes, and asked a riddle to all travellers, in order to let them pass and would eat those who could not answer the riddle. While working on the chemistry of the brain, the German-born British chemist J. L. W. Thudichum discovered this new type of molecules and in particular sphingosine, which presented many enigmas to its discoverer. “In commemoration of the many enigmas, which it presented to the inquirer, I have given the name of Sphingosin” (Thudichum 1884).
4.5.7 Saccharolipids in bacterial membranes
The last group of acyl-based lipids include saccharolipids, where the backbone for attaching the acyl chains are sugars, namely glucosamines and sometimes glucosamine disaccharides or sugar dimers (hence the prefix saccharo- for sugar backbone, by opposition to glycero- for glycerol backbone in glycerolipids; Fahy et al. (2005)). What a mouthful, yet again…! The most infamous saccharolipid is commonly referred to as Lipid A and is the part of endotoxins of Gram-negative bacteria that is inserted in outer monolayer of the outer membranes (Raetz and Whitfield 2002). Endotoxins are toxins for most animals. They are attached to the bacteria membranes themselves, as opposed to exotoxins that are released by bacteria in their environments. When bacterial cells are lysed by the mamalian immune system, fragments of membrane containing lipid A are released into the circulation, causing fever, diarrhea, and possible fatal endotoxic shock (also called septic shock). The Lipid A moiety is a very conserved component of the endotoxins. However Lipid A structure varies among bacterial species and Lipid A structure defines an overall host immune activation, sometimes violent (Wikipedia contributors 2019f). In other words, saccharolipids are bad news if they get into the blood systems of mammals…
](pictures/lipidA.png)
Figure 4.59: Chemical structure of lipid A as found in E. coli, and its place in the a bacterial endotoxin. Notice the two glucosamine bonded together and four fatty acids on one of them and two on the second. After Mike Jones
For our purpose here, saccharolipids and lipid A in particular (Figure 4.59) have the same basic structure of a hydrophilic head and hydrophobic tail. The role of the hydrophobic tail is fulfilled by fatty acids. The hydrophilic head is fulfilled by the the glucosamine and the two phosphates. Lipid A corresponds to the part of endotoxins of Gram-negative bacteria that is embedded in the membrane (Figure 4.59). Endotoxins, built from a lipid anchor and a polysaccharide chain are referred to as lipopolysaccharides, a mix between carbohydrates and lipids really.
In summary:
-
Sphingolipids play an analog role as those of phospholipids in the
membrane.
- The saturated aliphatic chain of sphingosine results in a straight aliphatic chain, as opposed to kinks observed in unsaturated fatty acids
- This associated with the amide bond between sphingosine and the saturated fatty acyl group generates ceramides, equivalent of diacyl-glycerols, which tend to be rather cylindrical in shape taking much less space in the membrane and less prone to move
- The accumulation of Sphingolipids, with that of cholesterol, near membrane nano-domains creates the conditions for the presence of liquid-ordered or gel-like phase in which membrane proteins can insert
- Saccharolipids are only present in bacteria membranes where they readily insert in the phospholipids membrane because of similar amphipathic properties
4.5.7.1 Other acyl-based lipids of biogeochemical significance
In addition to saturated and unsaturated fatty acyl moeities, other configurations of fatty acids play an important role in the fluidity of the membrane, but they only concern prokaryotic cells, some of which of biogeochemical significance. Some fatty acids are called branched fatty acids as they have methyl groups along their aliphatic chains. s and This results in less packing of the membrane, and therefore a higher fluidity of the membrane (e.g., Poger, Caron, and Mark 2014).
Figure 4.60: Examples of branched fatty acyl chains commonly found in bacterial membranes. The PPC letters stand for Palmitoyl PhosphoCholine, and the number-letter prefix varies depending on the presence, location, and number of methyl groups. (Further details in Poger, Caron, and Mark (2014))
Others are called cyclic chain fatty acids, where rings of cyclopropane (C3), cyclobutane (C4), up to cycloheptane (C7), are inserted at the ω end of the fatty acids (Figure 4.61). The effects of these ringed tails, as they increase space between fatty acid chains seem to increase the membrane fluidity, particularly for the unsaturated rings. However, the large saturated rings (C6 or C7), because of the space they take and the lack of electronic resonance, seem to reduce their own mobility, thereby reducing the overall fluidity of the membrane around them (Poger and Mark 2015b).
Figure 4.61: ω-Alicyclic Fatty Acids, i.e. cyclic rings inserted in the ω position of the fatty acyl moiety having 3 to 7 carbons in the ring (from Poger and Mark (2015b))
Cyclopropane inserted within the fatty acid chains do tend to create higher fluidity of bacteria membrane (e.g., Grogan and Cronan 1997; Poger and Mark 2015a, 2015b). Some cyclopropene fatty acids have been observed in plants cells as well. They seem to inhibit desaturation during the synthesis of fatty acids and pheromones in insects and so may protect plants against insect attack (W. (bill). W. Christie, n.d.).
Figure 4.62: Examples of cyclopropane fatty acids found in bacterial membranes. The PPC letters stand for Palmitoyl PhosphoCholine, and the number-letter prefix varies depending on the presence, location, and number of cyclopropane groups. (Further details in and after Poger and Mark (2015a))
Anammox bacteria, of the order of Planctomycetales, have recently been recognized to possibly have a major biogeochemical role as they can oxidize ammonium under anaerobic conditions (details in section 9.2). Ladderane lipids (named after the word ladder because of their shape) were reported in 1999, as part of the membrane lipids of the anammoxosome organelle of anammox bacteria (Sinninghe Damsté et al. 2002). These C17-C20 ladderane lipids contain three linearly concatenated cyclobutane rings and one cyclohexane or five cyclobutane rings (X and Y, respectively, in Figure 4.63). Ladderane fatty acids are esterified with methanol or the glycerol backbone, and the ladderane alcohols are ether-linked with glycerol, all in different combinations (Figure 4.63). First, these lipids seem not to have a phosphate or other polar moiety. Second, they readily assemble into very compact ladderane lipid sheets (right side of Figure 4.63), which has been surmized to largely lower the diffusion of toxic byproducts such as hydrazine (N2H4) and hydroxyamine (NH4OH) from the anammoxosome.
![Ladderane lipids as described in 1999 account for about 50% of the membrane lipids of the anammoxisomes. They are thought to assemble into very compact lipid sheets, giving rise to an exceptionally dense membrane, thus a tight barrier against diffusion, allowing the oxidation of ammonium under anaerobic conditions to proceed. After [@Sinninghe_Damste2002-sp]](pictures/ladderanes.png)
Figure 4.63: Ladderane lipids as described in 1999 account for about 50% of the membrane lipids of the anammoxisomes. They are thought to assemble into very compact lipid sheets, giving rise to an exceptionally dense membrane, thus a tight barrier against diffusion, allowing the oxidation of ammonium under anaerobic conditions to proceed. After (Sinninghe Damsté et al. 2002)
Archeabacteria, considered as the first phylogenic organism group, and now considered as one of the three groups with eubacteria and eukaryots, have membrane acyl-based lipids where the hydrophobic tails are bonded to the hydrophilic backbone through ether bond, and not ester bonds anymore (De Rosa and Gambacorta 1988). Additionally, their fatty acids are built upon isoprenoid chains (further details on isoprenoids in section 4.5.10), i.e., in this case saturated chains methylated every 4 carbons. This must affect the fluidity of the membrane.
![Isoprenoid diethers basic components of some complex lipids of archaebacteria [@De_Rosa1988-xd]](pictures/isoprenoids-FA.png)
Figure 4.64: Isoprenoid diethers basic components of some complex lipids of archaebacteria (De Rosa and Gambacorta 1988)
Possibly more surprising and showing how cell membranes evolved, the core membrane lipids of archeobacteria are bipolar amphipatic molecules with ‘fused’ hydrophobic isoprenoid tails, bonded with ether bonds to the hydrophilic heads on opposite sides to form isoprenoid tetraethers, and, have cyclic rings inserted in the isoprenoid tails. This can only add rigidity to the membrane, a feature that is obtained in eukaryotic cells with sphingolipids combined with cholesterol lipids.
![Isoprenoid tetraethers basic components of some complex lipids of archaebacteria [@De_Rosa1988-xd]](pictures/isoprenoid-tetraethers.png)
Figure 4.65: Isoprenoid tetraethers basic components of some complex lipids of archaebacteria (De Rosa and Gambacorta 1988)
but cyclobutane rings seem to create higher membrane compaction (Moss et al. 2018, more details in section 4.5.13.3).
Other fatty acids are oxidated and have hydroxy groups, others have one or several triple bonds (acetylenic fatty acids), while others have nitro groups added. This is a bit anecdotal here but more details may be found on the LipidWeb.
4.5.8 Summary about the acyl-based-lipids
Broadly, acyl-based lipids are at the basis of cell membrane formation, and serve as the energy storage molecules in organisms. Their long mostly-saturated aliphatic chains are able to store many electrons, which are physically stored as triacylglycerols in organisms as there are few free fatty acids. The long aliphatic chains are the reasons for the general hydrophobicity of lipids. The magic of these fatty acids (and sphingosine tails) is their ability to bind with more polar groups such as phosphate, choline, inositol, etc., thanks to a molecular backbone, giving many of the acyl-based lipids their amphipathic nature. This is the basis of all compartmentilization in living cells by the phospholipid bilayer, allowing for the creation of gradients, exchanges, barriers, etc., all needed to form organisms of several to billions of cells that need to interact and communicate together.
This concludes the part on acyl-based lipids. The next part explores the lipids which structures are originally based on chains of isoprene subunits. They play a complementary role of acyl-based lipids in membranes and play a major role as messengers, e.g., in the form of vitamins and hormones.
4.5.9 Overview of the isoprene-based lipids
4.5.9.1 Isoprenoids built from isoprene subunits
Everyone has heard about steroids. And everyone has heard about cholesterol. These are sterol-based lipids. They belong to a larger group of molecules, which includes prenol-based and steroid-based lipids, which have isoprene units as their common molecular skeleton. So no, you did not read monomer, you read unit, but honestly it would be tempting to use the term isoprene monomer and polymerization of isoprenes to form isoprenoid molecules or terpenes (literally derivatives of isoprenes) and their derivatives which include prenol-based and steroid-based lipids.
If you thought that the acyl-based lipids were complicated, think again, because prenol-based and steroid-based lipids will take you to the next level in the intricacy of lipid chemistry! At the same time, it really is fascinating and it opens the doors to molecules and name we have all heard about: vitamins or essential oils.
Etymology Corner
The words isoprene and terpene have rather convoluted etymologies. In 1860, the English scientist and analytical chemist Charles Greville Williams analyzed caoutchouc and gutta percha (latex from the Palaquium tree) by destructive distillation and obtained a large quantity of a light oil which he termed isoprene (Williams 1860). The term isoprene can be analyzed from iso- (“equal; different, isomeric”) + prop- (“three carbon prefix”) + -ene (“alkene suffix”). It is really unclear how Williams came up with this name. This is an unfortunate misnomer.
The word terpene is derived from the word “terpentine”, an obsolete form of the word “turpentine” (Wikipedia contributors 2019h). The latter seems to come from the Latin/French térébenthine, and Greek terebenthos (τ ε ρ ε β ι ́ ν θ ι ν ο ς), referring to the resin of the terebinth tree Pistacia terebinthus, which produces the pistachio nut. Turpentine resins, secreted by resinous trees to protect wounds or cuts in the trunks, has been harvested throughout the world. The one harvested from the long leaf pines (Pinus lacustris) of the coastal plain of the Eastern USA was highly sought after from the 17th to 19th centuries. It made the wealth of cities like Wilmington, N.C., along with tar and pitch (sticky liquids produced by burning pine branches and logs very slowly in kilns (History 2012)) used in the naval industry.
The pine resin, after purification and distillation, separates into a liquid aromatic part, turpentine or oil of turpentine, and a solid part called rosin or colophony. Rosin is extensively used (among many others) for its friction-increasing capacity, particularly on bow hair of string instruments so it can grip the strings and make them speak, or vibrate clearly. Turpentine oil was used in making paint, paint thinner, and various medicines (History 2012). Many terpene molecules described in this chapter are present in the oil of turpentine.
So isoprene is a C5 double unsaturated molecule (Figure 4.66), which animals and plants produce, the latter to protect leaf cells against extreme heat. It turns out that it is the assemblage of two isoprene units bonded to a pyrophosphate (called geranyl pyrophosphate - GPP; Figure 4.66) that is the beginning of many isoprenoids, otherwise also named terpenes (etymology explained above).
4.5.10 Prenol or isoprenoid lipids
The name for the family comes from the alcohol version of isoprene, called prenol (Figure 4.66), where the hydroxy group takes advantage of the original double bond on the tail of the molecule (carbon 4; Figure 4.66), which relocates the remaining double bond between carbons 2 and 3 (Figure 4.66). Geranyl pyrophosphate is at the basis of many polyprenols and just about all terpenes. Polyprenols play an important function acting as natural bioregulators and are found in small quantities in various plant tissues (Wikipedia contributors 2019c).
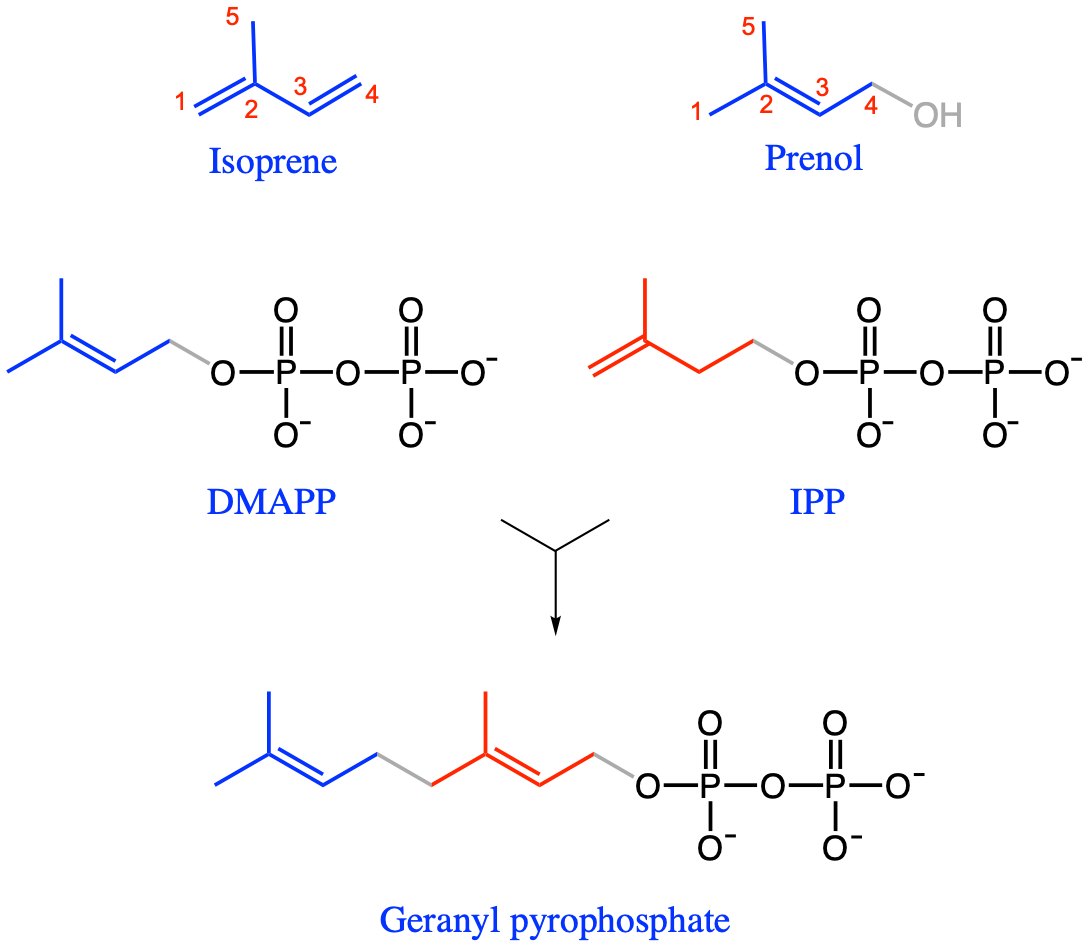
Figure 4.66: Isoprene and prenols; Geranyl pyrophosphate is the precursor of most terpenes or isoprenoids. Geranyl pyrophosphate is formed from DiMethylAllyl PyroPhosphate (DMAPP) and its isomer Isopentanyl PyroPhosphate (IPP)
4.5.10.1 Many familiar isoprenoids
Isoprenoids or terpenes have several important characteristics: they tend to be very aromatic, have the tendency to not stay as straight molecules as depicted in Figure 4.66, but rather to fold into carbon rings.
 and [Hbf878](https://commons.wikimedia.org/w/index.php?curid=64276853)](pictures/terpene-cyclization.png)
Figure 4.67: Examples of two monoterpenes formed by the propensity of prenols to form cycles. After Fred the Oysteri and Hbf878
Because geranyl-pyrophosphate is the initial building block of most terpenes, and because it has two isoprene units (Figure 4.66), terpenes tend to have even numbers of isoprene units (although there are many isoprenoids with odd numbers of isoprene units, e.g. Table 4.2). Hemiterpenes, Monoterpenes, Sesquiterpenes, diterpenes, triterpenes, and tetraterpenes respectively refer to isoprenoids with 1, 2, 3, 4, 6, and 8 isoprene subunits (Table 4.2).
| Terpene type | Examples |
|---|---|
|
Hemiterpenoids (half-terpene) |
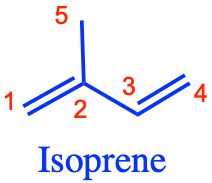 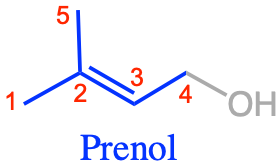
|
| Monoterpenoids |
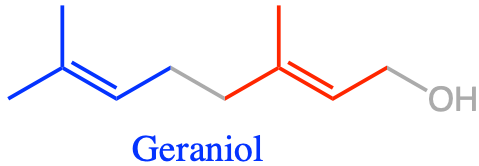 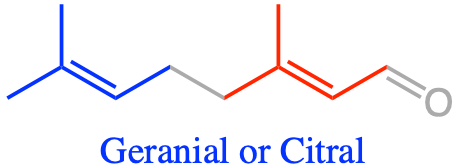 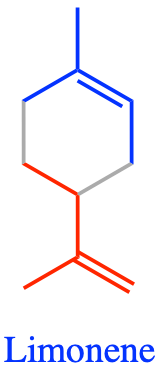 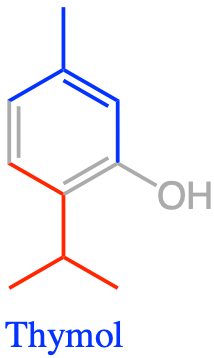 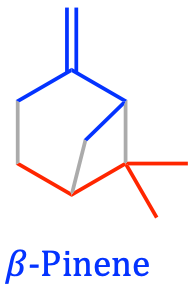
|
|
Sesquiterpenoids (one & a half terpene) |
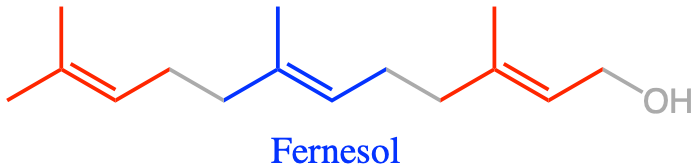 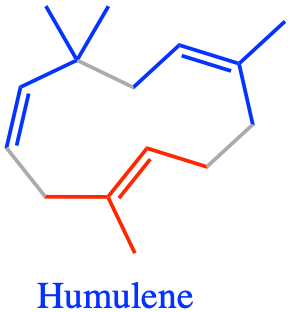
|
| Diterpenoids |
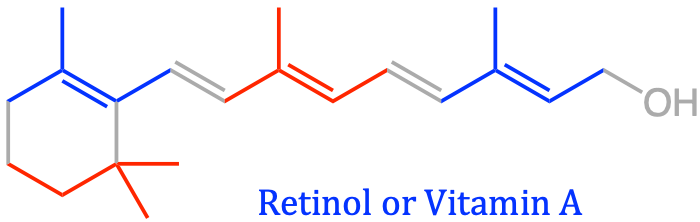
|
| Triterpenes |

|
| Tetraterpenes |
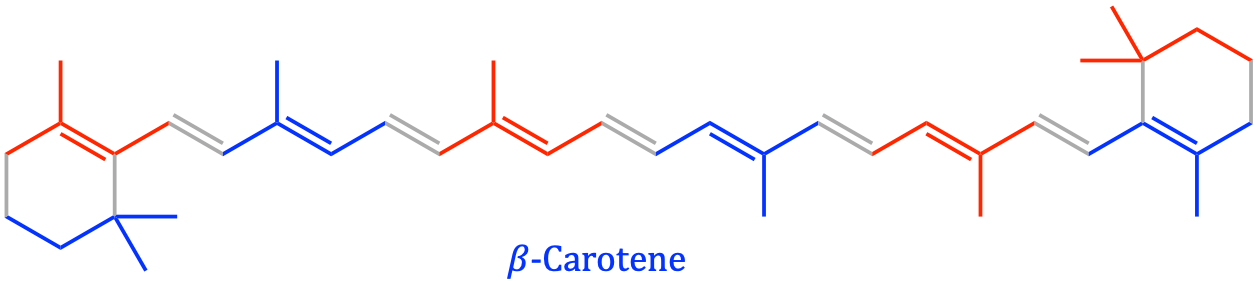 
|
The propensity of prenols to form cycles is at the basis of the formation for example of the lanosterol, precursor of all steroid lipids, from squalene (a common oil found in shark liver; Table 4.2 and Figure 4.71). Vitamin A (retinol) is a bi-product of β-carotene, both of which exhibit carbon rings (Table 4.2). Carotene is a photosynthetic pigment important for photosynthesis absorbing in the ultraviolet, violet, and blue light and scatter orange or red light, and (in low concentrations) yellow light. Carotene is responsible for the orange color of the carrots (hence its name) and many other fruits and vegetables. As a precursor to vitamin A, carotenes, must be ingested by humans. Xanthophylls are photosynthetic pigments giving the yellow color, even in egg yolk, located mostly in leaves where they act to modulate light energy. They are very close to, and essentially are oxygenated versions of carotenes (Table 4.2).
The cycling propensity of isoprenoids also exist for many aromatic terpenes referred to as essential oils. Contrary to what the word essential means for fatty acids or amino acids, i.e., that humans do not synthesize them and must be acquired through food, essential oils refer to the propensity of these molecules to become very volatile and contain the “essence of” the plant’s fragrance. Molecules such as geraniol are found on the leaves of geranium plants, geranial or citral give a strong lemon (citrus) odor, limonene is found in many citrus plants, pinene in pine, thymol in thyme, menthol in mint (actually a terpenoid because it has an oxygen atom, and not a terpene sensu stricto, which have only carbon atoms), humalene in humulus lupulus or hops in Latin, etc. In fact, many students have heard about terpenes because they are synthesized on the trichomes or plant hair of cannabis leaves, and offer various aromas for their use, along with possible medical benefits.
Isoprene and many essential oils, being very volatile, are closely involved in production of the air pollutant, ozone. In addition, when they are oxidized by atmospheric ozone, ·OH, or NOx radicals, aerosols may form that cause scattering of the sunlight; since the intensity of the scattering is proportional to \(1/ \lambda^4\), the short wavelengths λ are enhanced in the scattered light, making it look blue (Rayleigh scattering). This is the main explanation for, e.g., the appearance and the name of the Blue Ridge Mountains of North Carolina which hosts many conifer species.
Some authors question whether the ‘essential oils’ and many terpenoids belong to the lipid family at all (e.g., W. (bill). W. Christie (n.d.)), but we thought that it was a missed opportunity not to mention them here.
4.5.10.2 Vitamins E and K
Finally, isoprenoid side chains are present in quinone based isoprenoids such as vitamin K, needed for blood coagulation (Koagulation in Danish), plastoquinone and ubiquinone involved in the electron transport chains of, respectively, the chloroplasts and mitochondria. The long isoprenoid chains of plasto- and ubiquinone allow these molecules to readily insert within the phospholipid bilayer of the membrane of these organelles.
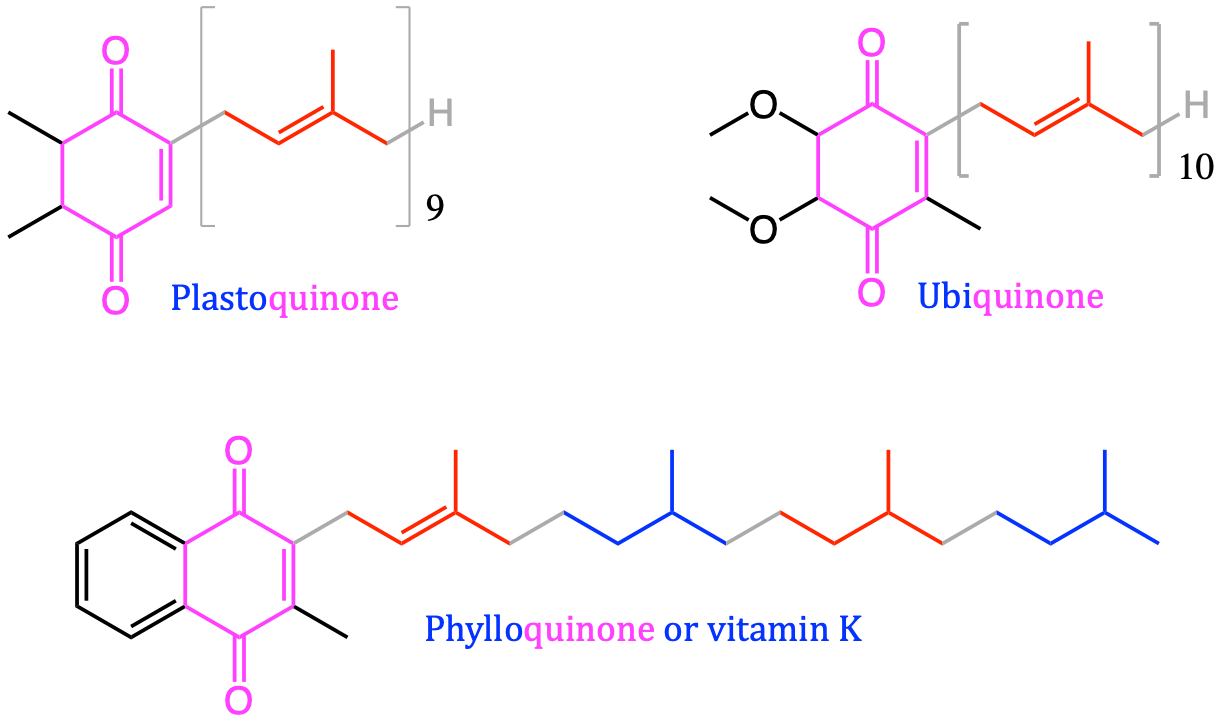
Figure 4.68: Quinone based isoprenoids including vitamin K, needed for blood coagulation (Koagulation in Danish), plastoquinone and ubiquinone involved in the electron transport chains of, respectively, the chloroplasts and mitochondria. The quinone functional group is represented in magenta
The ubiquinone can be an electron transport molecule thanks to the quinone moeity, which can accept two electrons and be reduced into ubiquinol (Figure 4.69). It can easily be oxidized back into ubiquinone thanks to the electron resonance of the quinone moeity, and therefore ‘liberate’ its electrons to be ready to transport more electrons during the electron transfer chain. Ubiquinone is often referred to as the coenzyme Q.

Figure 4.69: The reduction of ubiquinone (or coenzyme Q) to ubiquinol (QH2). The quinone functional group is represented in magenta
Tocol-based isoprenoids like tocopherols and tocotrienols, collectively known as tocochromanols (W. (bill). W. Christie, n.d.) including molecules such as vitamin E, are essential for animals and humans, which must ingest enough of them for their growth. In plants, they are especially important as antioxidant molecules, limiting the damage from photosynthesis-derived reactive oxygen species during conditions of oxidative stress, including high-intensity light stress (W. (bill). W. Christie, n.d.).
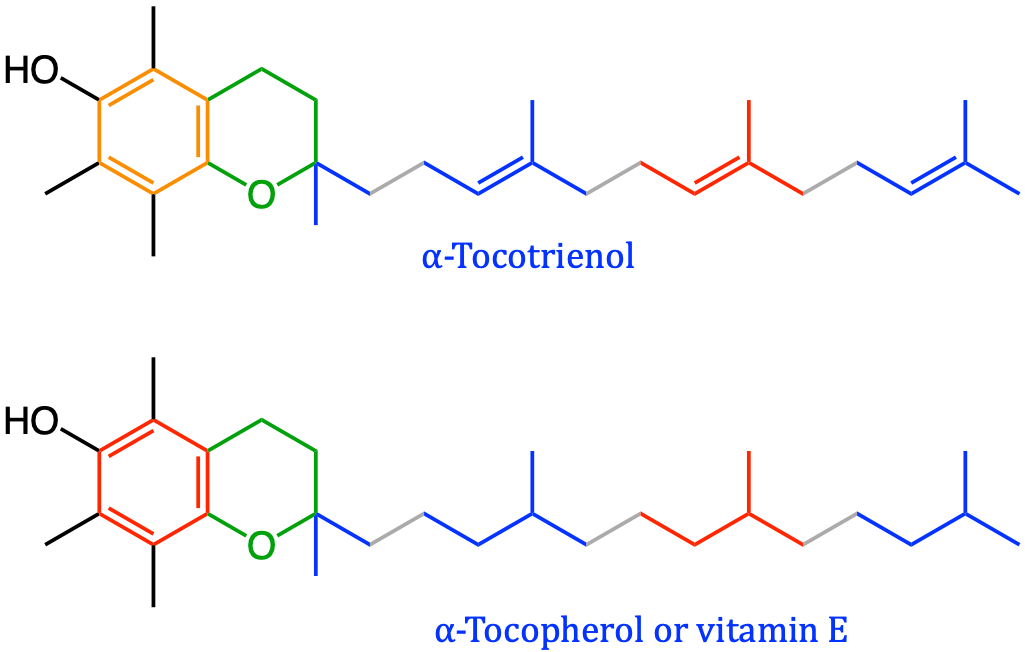
Figure 4.70: Tocol-based isoprenoids including vitamin E, essential for animals and humans, and acting as important antioxidant molecules
In summary:
- Prenol or isoprenoid lipids comprise a very large number of molecules based on the common isoprene C5 building unit.
- Molecules with C and H atoms only are called terpenes, the others isoprenoids
- Isoprenoids have the propensity to be assembled in pairs because geranyl pyrophosphate (two isoprene units) is the molecule upon which most of them are built. As a result, molecules with 4, 6, or 8 isoprene units are called di-, tri-, and tetraterpenes(oids)
- Isoprenoids have the propensity to form carbon rings, which are among the reasons why they are so aromatic to our olfactory sense.
- Essential oils, although not always classified as lipids, provide everyday life experience of isoprenoids in the smell of mint, pine, lemon, thyme, lavender, etc.
- Isoprenoids such as carotene, xanthophyll (tetraterpenoids) play a major role in capturing light energy in photosynthesis, while plasto- and ubiquinone play a major role in the electron transfer chain in the chloroplast and mitochondrion membranes
- Vitamin A, E, and K are prenol lipids
4.5.11 Sterol lipids
4.5.11.1 Cholesterol and oxysterols
The most famous of the sterol lipid is cholesterol as it plays an essential role in the animal cell membrane rigidity as already described in section 4.5.2 above. All sterol lipids are derived from the triterpene squalene (Table 4.2 and 4.71), eventually leading to two slightly different precursors: lanosterol for animals and fungi, and cycloartenol for plants and algae. Because of this distinction, phyto- and zoosterols are a bit different. Sterol and steroid lipids all have fused rings and a planar geometry, which gives them rigidity and strength. As a result, they play an essential role in membrane stability and particularly in lipid rafts where the membrane has less a fluidic property, and more of gel like properties (details in section 4.5.2).
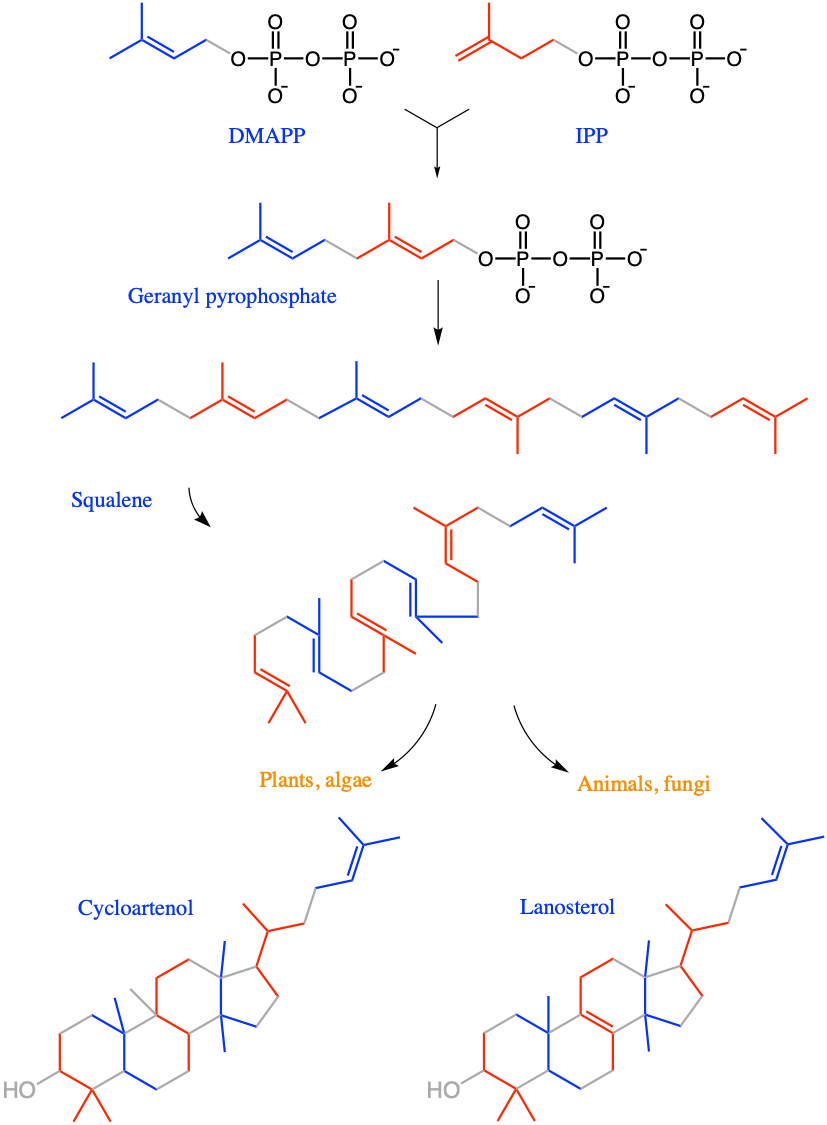
Figure 4.71: Synthesis of lanosterol and cycloartenol, the precursors of respectively the zoo- and phytosterols lipids from DiMethylAllyl PyroPhosphate (DMAPP) and its isomer Isopentanyl PyroPhosphate (IPP), geranyl pyrophosphate (GPP), to squalene, before it goes into cyclization to form four fused carbon rings
Zoo- and phytosterols are consistent within their kingdoms, but in reality extremely close at the molecular scale and in their functions of stabilizing the cell membranes near nano-domains and stabilizing proteins in the membrane as cholesterol may strongly bind to them (W. (bill). W. Christie, n.d.). Zoosterols are based upon cholesterol molecule, a C27 molecule, or triterpene that has lost 3 methyl groups. The oxygenated derivatives of cholesterol are called oxysterols and correspond to the partial oxidation of cholesterol (e.g., cerebrosterol in Figure 4.72).
Etymology Corner
The English word cholesterol, comes from the French cholestérol, itself derived from the word cholesterine proposed by French chemist Michel Engène Chevreul in 1816: “Je nommerai cholesterine, de χολη [choli], bile, et στερεος [stereos], solide, la substance cristallisée des calculs biliares humains, … I will name cholesterine — from χολη (bile) and στερεος (solid) — the crystalized substance from human gallstones …” (Chevreul 1816). François Poulletier de la Salle seems to be the first actual discoverer of cholesterol crystals in 1758 or 1769 although he did not publish his results, which were later quoted by his collaborators.
4.5.11.2 Phytosterols and hopanoids
Higher plant sterols are very close to animal cell cholesterol, with the variations on the C24 (additions of methyl or ethyl groups) and double bonds between C22 and C23 (e.g., campesterol in Figure 4.72). Ergosterol, the main sterol in fungi and yeasts, has an additional double bond between C7 and C8 (Figure 4.72). It is remarkable to observe that there is little variation in animal sterols, cholesterol being the dominant form, other than the oxidative derivatives, while there are more than 8 plant sterols identified, with small variations among them.
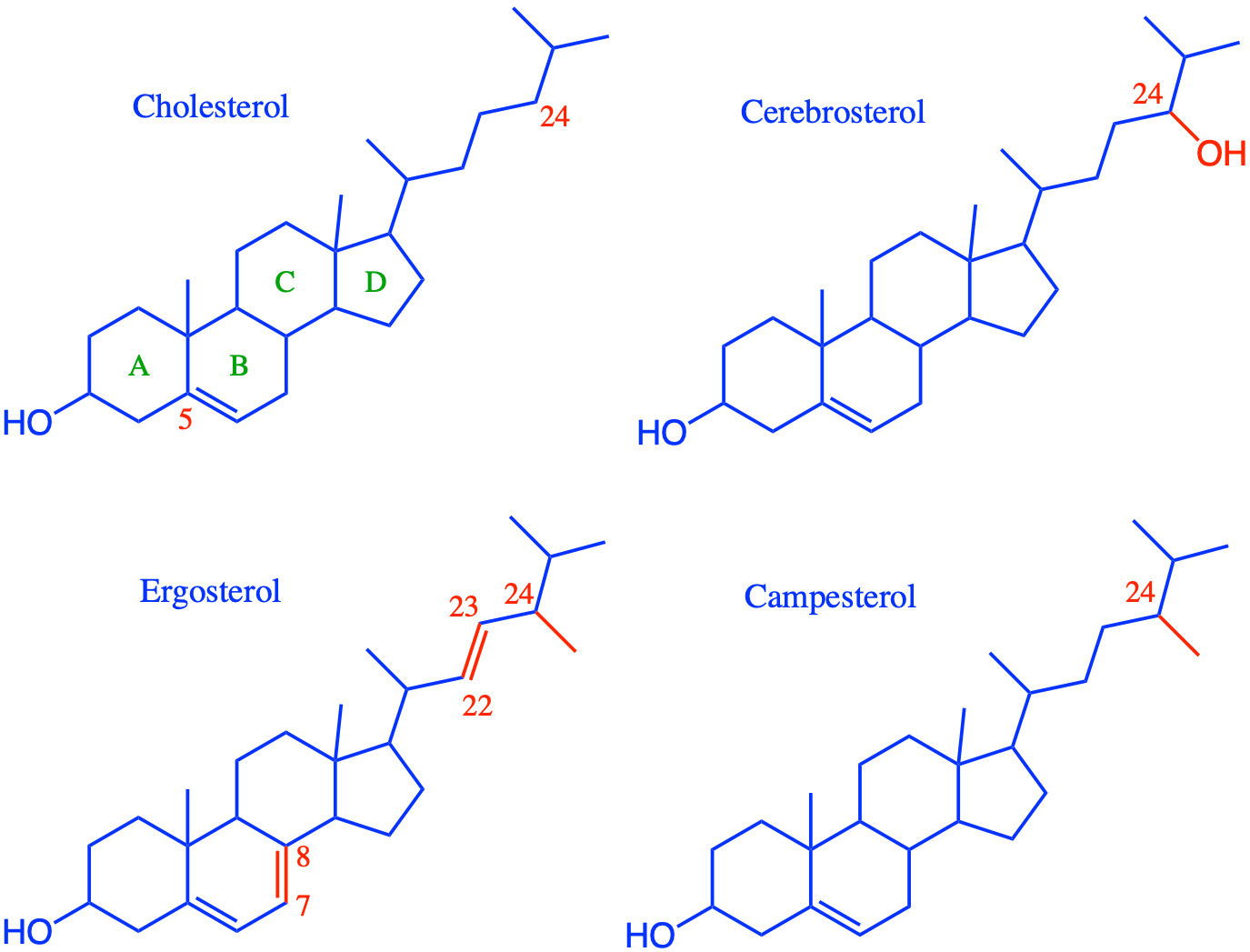
Figure 4.72: Cholesterol is the most common zoosterol. Cerebrosterol is an oxidated derivative of cholesterols in animals. Ergosterol is the equivalent of cholesterol for fungi and yeast. Campesterol is one of the many plant sterols characterized by additional side chains on the C24. All atoms and bonds differing from the animal cell cholesterol are highlighted in red
Bacteria and other prokaryotic organisms such as blue-green algae do not in general contain any of the conventional sterols found in plants and animals (there are always exceptions), but rather many species have related molecules, i.e. pentacyclic triterpenoids based on a hopane skeleton with four cyclohexane rings and a cyclopentane E-ring and termed ‘hopanoids’ Perhaps the most abundant hopanoid in living organisms is tetrahydroxybacteriohopane (W. (bill). W. Christie, n.d.).
Figure 4.73: Tetrahydroxybacteriohopane, the most abundant hopanoid in bacteria and other prokaryotic organisms, has very similar functions to those of sterols in the membranes of animals and plants in that they can intercalate into phospholipid bilayers and modulate the fluidity of membranes by interacting with their complex lipid components
4.5.11.3 Steroid signal molecules
Among the most remarkable sterol lipids are the steroid hormones, and particularly the sex hormones and cholecalciferol hormone better known as vitamin D.
Estradiol and testoterones have lost the aliphatic chain of the reference cholesterol. Estradiol is a naturally occurring hormone that circulates endogenously within the human body. It is the most potent form of mammalian estrogenic steroids and acts as the major female sex hormone. As such, estradiol plays an essential role in the regulation of the menstrual cycle, in the development of puberty and secondary female sex characteristics, as well as in ageing and several hormonally-mediated disease states. Testosterone is the most important androgen, i.e., the major male sex hormone, in potency and quantity. It is remarkable to see how apparently relatively small differences between the two molecules can make such fundamental differences!
Cholecalciferol (vitamin D3) is a steroid hormone produced in the skin when exposed to ultraviolet light or obtained from dietary sources. The active metabolite of cholecalciferol, calcitriol plays an important role in maintaining blood calcium and phosphorus levels and mineralization of bone. Appropriate levels of vitamin D must be upheld in the body in order to maintain calcium and phosphorus levels in a healthy physiologic range to sustain a variety of metabolic functions, transcription regulation, and bone metabolism.
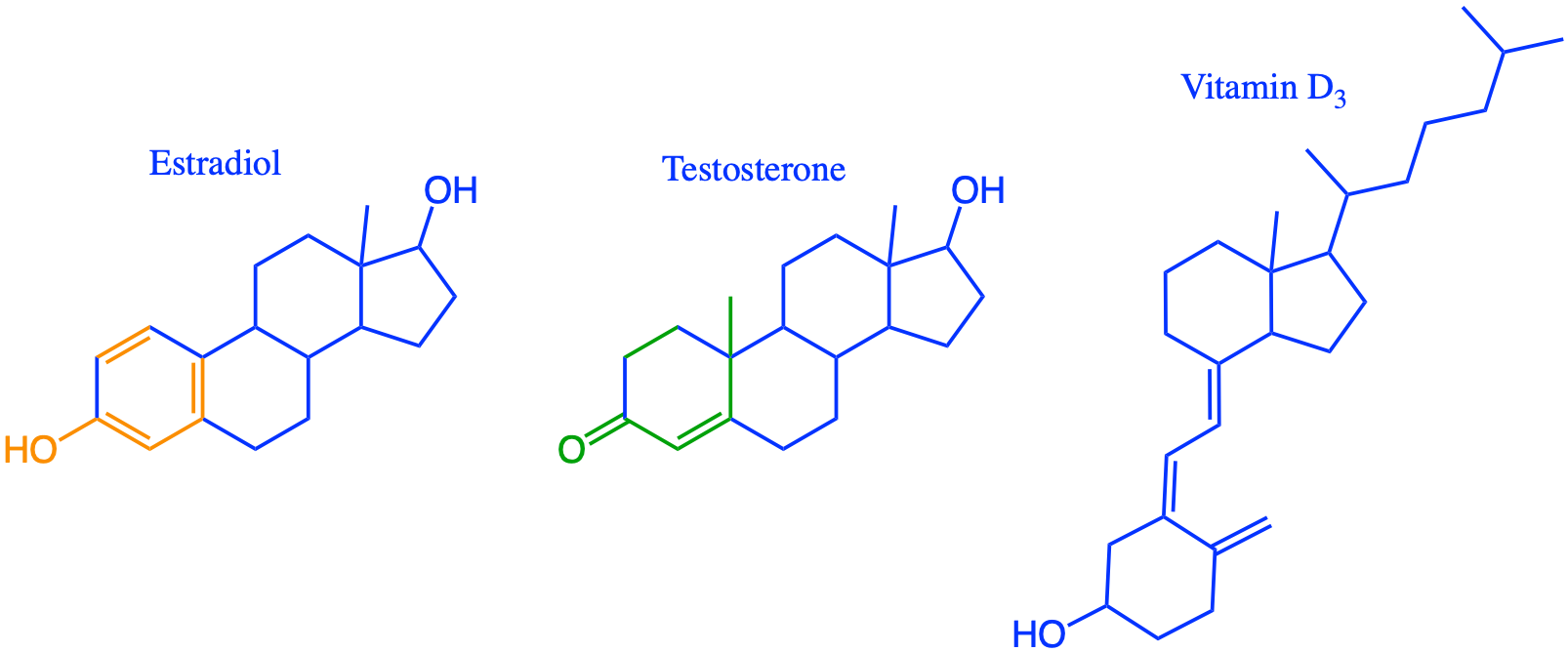
Figure 4.74: Estradiol and testoterone as the major female and male sex hormones, respectively. All differences in atoms and bonds are highlighted in orange and green. Cholecalciferol (vitamin D3) is a metabolite of cholesterol and necessary for the calcium and phosphate regulation in the human body
The transport of sterol lipids through vascular animal organisms is problematic because, despite the hydroxy group of the A carbon ring of cholesterol (Figure 4.72) that make sterol lipids somewhat polar, cholesterol is insoluble in water, very much like all lipids and in particular triglycerides. A specialized type of pseudo-organelles called lipoproteins transports hydrophobic lipids through the body. This organelle is formed by a single layer of phospholipids assembled as a sphere creating a hydrophilic outer surface soluble in water, and a hydrophobic compartment inside in which cholesterol, cholesterol esters and triglycerides are stored. Inserted proteins called apolipoproteins provide structural, communication and enzymatic activities.
](pictures/Chylomicron.png)
Figure 4.75: Chylomicron, or the largest of the lipoproteins which serve in transporting lipids in vascular animal organisms. T: Triglycerides; C: Cholesterol; ApoA, ApoB, ApoC, ApoE: lipoproteins By Xvazquez
Depending on the size of the sphere, scientists have named these High Density Lipoproteins (HDL; 5-12 nm diameter), Low Density Lipoproteins (LDL; 18-25 nm diameter), Intermediate Density Lipoproteins (IDL; 25-35 nm diameter), Very Low Density Lipoproteins (VLDL; 30-80 nm diameter), and chylomicrons (75-1200 nm diameter) (Feingold and Grunfeld 2018). The HDL and LDL acronyms are rather well known and are common indicators reported in routine blood analyzes. Cholesterol in lipoproteins is often esterified with fatty acids to form sterol esters, making the molecules much less polar than free cholesterol.
Interestingly, cholesterol is not metabolized by humans as a source of energy, despite the fact that it stores quite a few electrons. Instead, cholesterol is a precursor of hormones, vitamin D, and its metabolites (e.g., bile acids) serve as surfactant in the digestive system to help digestion and assimilation of nutrients and essential molecules (e.g., amino-acids, monosaccharides, essential fatty acids).
In summary:
- Almost all sterol and steroid lipids have four fused rings and a planar geometry, which gives them rigidity and strength. These properties are essential for their functions in cell membranes
- They are all derived from the triterpene squalene
- Zoo- and phytosterols play an essential role in the membrane nanodomains by rendering the membrane in a liquid-ordered phase, i.e., more gel-like and more rigid
- Sterols tend not to serve as a source of energy in animals, but rather are degraded into metabolites that serve as surfactant in the digestive system to help digestion and assimilation of nutrients and essential molecules (e.g., amino-acids, monosaccharides, essential fatty acids)
- Animal sterols (with triglycerides) being hydrophobic are carried in the blood in specialized single phospholipid layered vesicles called lipoproteins, the most known of which are HDL and LDL, usually in the form of sterol esters
- Essential metabolites of cholesterol include sexual hormones and vitamin D
4.5.12 Summary about the isoprene-based lipids
Broadly, isoprene-based lipids are all based on isoprene units, which have the capacity to stay as linear chains, or form saturated and unsaturated carbon rings. The cyclization is complete with sterol lipids where mostly four fused rings and a planar geometry are at the basis of the structural strength of many zoo- and phytosterols when inserted in the acyl-based bilayer of membranes. Sterol metabolites such as steroid hormones play a major role in the development of animals. Isoprenoids such as prenol lipids play important role in energy capturing and electron transfer, as well as communication molecules, including vitamins and hormones.
This concludes the part on isoprene-based lipids. The next part briefly presents other lipids or biological importance we thought would fit better in their own part.
4.5.13 Other notable lipids
4.5.13.1 Waxes as fatty acid esters
There is no satisfactory definition of the word “wax” in chemical terms. It is derived from the Anglo-Saxon word “weax” for beeswax, so a practical definition of a wax may therefore be “a substance similar in composition and physical properties to beeswax”. Biochemists often link waxes with the thin layer of fatty constituents that cover the leaves of plants or provide a surface coating for insects or the skin of animals for which primary requirements are spreadability and chemical and metabolic stability. Such surface waxes are produced by specialized cells or glands, and all tend to contain wax esters as major and perhaps defining components, i.e. esters of long-chain fatty alcohols with long-chain fatty acids. (W. (bill). W. Christie, n.d.).
Most waxes are formed by two (fatty acid + fatty alcohol) or three moieties (fatty acid + fatty alkane-di-ol + fatty acid), in which case they are referred to as diester waxes. Waxes form the cuticle of plant leaves, but are also secreted by specialized glands in animals, in which case they tend to be associated with triacylglycerols and/or sterol esters. The uropygial gland of birds produces waxes gives feathers their water tightness. Spermaceti or the substance present in sperm whale and skulls of other dolphin and whales, is made by 75% of cetyl palmitate and 25% of triacylglycerols. The other animal wax of commercial value is wool wax of lanolin having waterproofing properties that aids sheep in shedding water from their coats. Lanolin contains up to 50% wax esters and 33% sterol (lanosterol) esters (W. (bill). W. Christie, n.d.).
4.5.13.2 Polyketides
Polyketides are a large group of secondary metabolites which either contain alternating carbonyl and methylene groups (-CO-CH2-) (Wikipedia contributors 2020a). Many mycotoxins produced by fungi are polyketides or polyketide derivatives and many are commonly used as antimicrobial, antiparasitic, and anticancer agents. Important examples of these drugs include erythromycins, tetracylines, nystatins, avermectins, and antitumor epothilones (Fahy et al. 2005).
Fahy et al. (2005) classify them as lipids while others (e.g., W. (bill). W. Christie (n.d.)) do not.
4.5.13.3 Natural cyclic fatty acid based lipids
Branched-chain fatty acids are common in bacterial and archaeal membranes where their concentration often exceeds that of linear-chain fatty acids. The variations in the presence, nature, and number of branching groups in fatty acids lead to distinct physicochemical properties of the lipids that in turn result in biological membranes with unique structural and functional properties (Poger and Mark 2015b).
Some bacteria and Archea have peculiar fatty acids chains that include cyclic The physiological rationale for cyclopropane ring formation in bacterial membranes remains obscure.
There are many other lipids that have been described in detail (e.g., Fahy et al. (2005); W. (bill). W. Christie (n.d.)), but we decided that they would not aid to synthesize what lipids are.
In summary:
- “Lipids are fatty acids and their derivatives, and substances related biosynthetically or functionally to these compounds” (W. (bill). W. Christie, n.d.)
- Long aliphatic chains may store many electrons, thus making lipids energy storage molecules
- Fatty acyl chains open the possibility for amphipatic properties with hydrophobic tails and hydrophilic heads, which allows for the formation of very tight membranes and compartmentalization of the cell in organelles
- Phosphates play an essential role in the structure of acyl-based membrane lipids and on the polar nature of the heads (along with moeities containing nitrogen)
- The methylated and unsaturated aliphatic chains (e.g., isoprenoids), tend to form carbon rings, yielding lipids such as sterols which are small, yet strong enough to rigidify cell membranes
4.6 Phenolics and polyphenols
This chapter is still under construction
Contrary to the previous carbohydrates, proteins, nucleic acids, and lipids, all considered to be primary metabolites, i.e., directly involved in normal growth, development, and reproduction of cells and organisms, phenolics and polyphenols are considered as secondary metabolites, i.e., not directly involved in these processes, but recognized to have an important ecological function. For this reason they rarely appear in textbooks introducing the biochemistry of life. We have decided to remedy this error by specifically crafting a section dedicated to these molecules so important to ecological engineering.
4.6.1 The impermeable world of phenolics
With the phenolics, lie the “tastes and the colors of the world” (Sélosse 2019). The complexity of these secondary metabolites does not only come from their assemblages in di-, and polymers, but also from the extraordinary diversity of what one might call the phenolic monomers…! If you thought lipids were complicated and diverse, phenolics are not any simpler.
Thanks to lignins, nearly 40% of the carbon atoms stored in the phytosphere belong to phenolics or polyphenol molecules! This group is thus anything but insignificant…! Yet, in ecological engineering, we have not fully taken the measure of how important these molecules truly are, and, until now, we have mostly ignored them although they may very well be “the elephant in the room”… To our defense, there are reasons for this as we shall see. So, what are phenolics and why do they matter?
![Polyphenols are highly represented in fruits and vegetables and make for their great diversity of colors and tastes [figure obtained from @Quideau2011-ei]](pictures/phenolics.png)
Figure 4.76: Polyphenols are highly represented in fruits and vegetables and make for their great diversity of colors and tastes (figure obtained from Stéphane Quideau et al. 2011)
Phenolics are sometimes loosely referred to as tannins (Sélosse 2019). Phenolics include molecules that have an aroma to our nose, that feel astringent in our mouths, that generate for a good part the colors of flowers or of tree leaves in autumn, or that play a fundamental structural role for plants (e.g., lignins) to erect themselves in a very low density aerial milieu (i.e., the air). Phenolics have antibiotic properties, protect many plants from insects, and define to a large extent the quality of organic matter and the rate at which its energy can be released in soil and in sediment. This is why their role is crucial in ecological engineering and deserves all our attention. Additionally, phenolics and polyphenols have also received quite a bit of attention from the general public for the last 30 years as they have been found to provide human health benefits.
As is often the case in science, there is a battle for the naming of a molecular group and which molecules should belong, or not… Sélosse, in his fantastic book written for the general public (Sélosse 2019), solves the problem by calling them tannins. This helps connect them with everyday life experience as many phenolics are indeed true tannins. In English, the word phenolics seems to be rather efficient to put into one term a large variety of molecules, although the general public cannot directly relate to them… In short, all these phenolic molecules have one or more aromatic rings with one or more hydroxy groups. The basis is thus the phenol molecule, i.e., an aromatic ring of which at least one carbon has been oxidized such that its hydrogen has been replaced by one hydroxy -OH group (Figure 4.77; also described is the section on aromatic hydrocarbons).
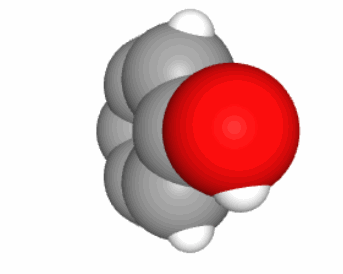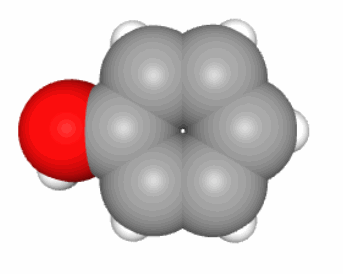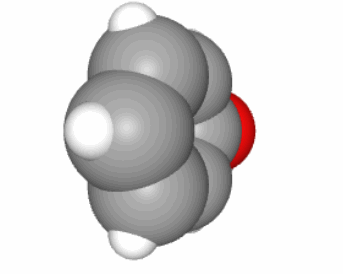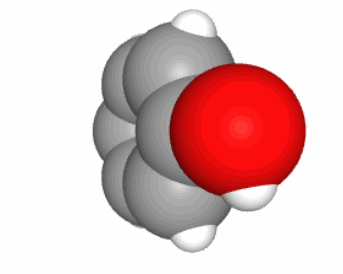
Figure 4.77: Skeletal formula (left), Lewis dot structure (center), and 3D space-filling animated view of phenol (right, grey = C atom, red = oxygen atome, white = hydrogen atom) showing the hydroxy group on one of the carbons of the benzene or aromatic ring
However, not all organic molecules that have phenols or phenyl groups belong to the phenolics group…! Think about the phenylalanine amino acid for example. Things would have been too simple otherwise. Everybody agrees that phenolics only contain CHO atoms, no N,S, or P (well almost…). The most abundant, other than lignins, are called the polyphenols, and have captured much of the scientific attention and beyond. Thanks to the antioxidant properties of many of them, the term polyphenols has also been used to describe molecules that only have one phenol moiety… This has caused quite a bit of confusion. Hardcore chemists have had their own discussion on what constitute phenolics and/or polyphenols and discussions are on-going (e.g., https://www.groupepolyphenols.com/). Below are some exerts from experts in the domain that illustrate the struggle of defining phenolics and polyphenols.
The term “polyphenol” should be used to define compounds exclusively derived from the shikimate/phenylpropanoid and/or the polyketide pathway, featuring more than one phenolic unit and deprived of nitrogen-based functions. This definition lets out all monophenolic structures, as well as all their naturally occurring derivatives such as phenyl esters, methyl phenyl ethers and O-phenyl glycosides. However, investigations on these compounds, which are often the biogenetic precursors of “true” polyphenols, definitely have their place in polyphenol research, but qualifying them as polyphenols is pushing it too far (S. Quideau, n.d.).
The inclusion of monophenolic compounds in polyphenol-oriented research can perhaps find its justification through an important property that all phenols share to some extent, and that is their capability to scavenge oxidatively-generated free radicals such as those derived from lipids and nucleic acids. This antioxidant activity of phenols is frequently cited to be the main event responsible for the prevention of age-related diseases such as neurodegeneration, carcinogenesis and cardiovascular diseases, including atherosclerosis, by phenol/polyphenol-rich diets. (S. Quideau, n.d.)
Thus, as a general rule recently proposed by Quideau et al. (2011), the terms ‘plant phenolics’ should be strictly used to refer to secondary natural metabolites arising biogenetically from either the shikimate/phenylpropanoid pathway, which directly provides phenylpropanoids, or the ’polyketide’acetate/malonate pathway, and which fulfill a very broad range of physiological roles in plants (Lattanzio 2013).
Has this clarified what phenolics are or are not…? Probably not so much, and this would be hardly surprising as the shikimate/phenylpropanoid and the ‘polyketide’ acetate/malonate pathways are not metabolic pathways everybody can relate to, right…? The world of phenolics is a bit impermeable to new comers, one has to admit! As a naturalist, classifications that relate moieties and molecules together are appealing to me and I will use the schemes proposed by Lattanzio, and Tsimogiannis and Oreopoulou to describe in hopefully enough details what phenolics are (Lattanzio 2013; Tsimogiannis and Oreopoulou 2019):
Phenolics can be classified into monomeric, dimeric, oligomers from condensation of different monomers, and polymeric phenols (Figure 4.78):
- Among the monomeric phenols, one can distinguish three classes:
- a single benzene ring (C6 class)
- a C6 ring with an attached carbon chain containing one to four or seven carbon atoms (C6-Cn class, n=1 to 4, 7)
- a more complex skeleton in which the carbon chain is further attached to a second benzene ring (C6-Cn-C6 class, n=1,2,3,7). The C6-C3-C6 category has historically been particularly studied
- Many of the monomeric phenols serve as monomers for polymeric phenols, among which one can distinguish:
- phenolic dimers [(C6-C1)2, (C6-C3)2, (C6-C2-C6)2, (C6-C3-C6)2]
- oligomeric products derived from condensation reactions (not represented in Figure 4.78)
- the polymers with general formulas [(C6)n, (C6-C1)n, (C6-C3)n, and (C6-C3-C6)n]
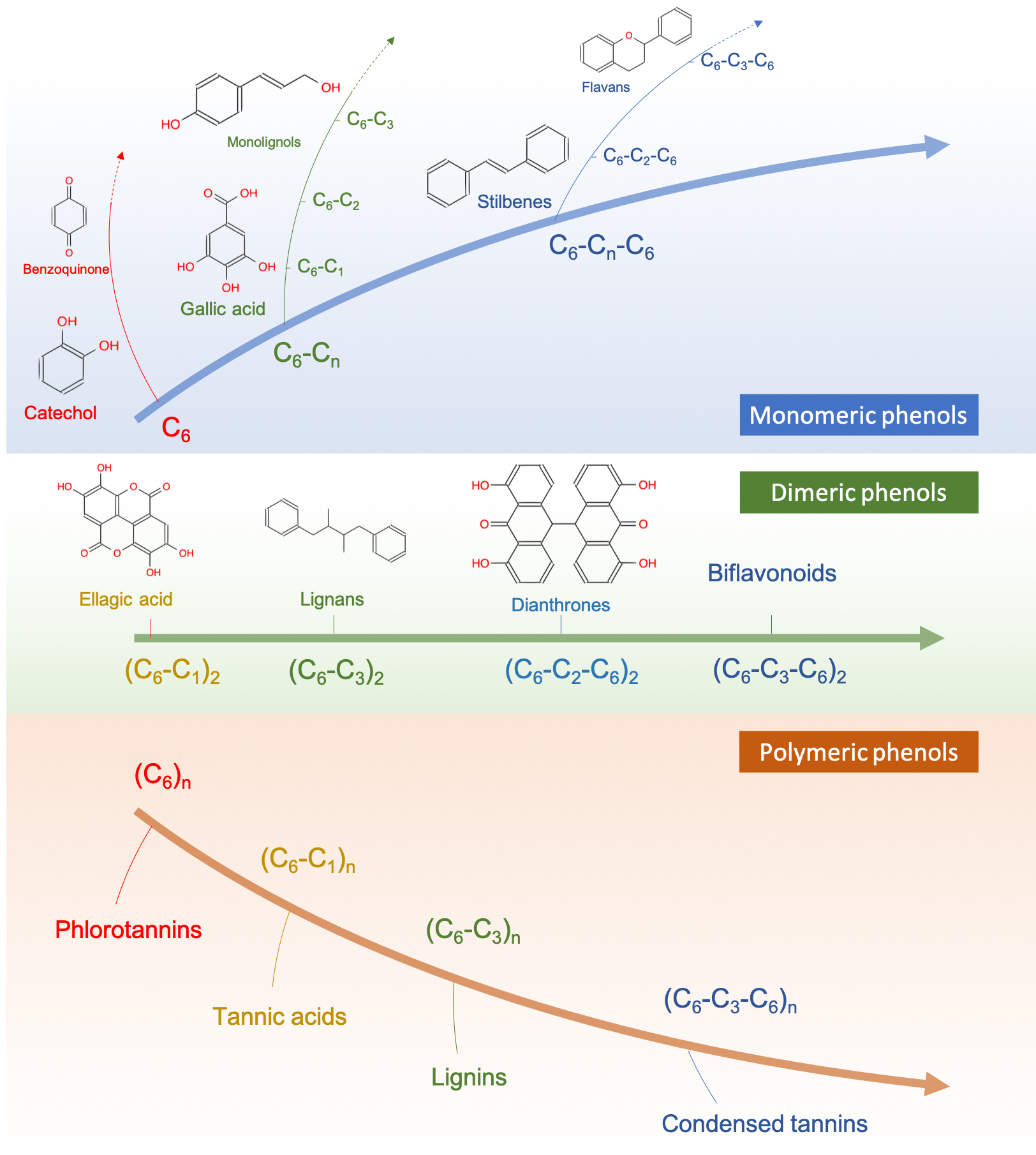
Figure 4.78: Attempt to represent the different classes of phenolic compounds existing in nature with some examples illustrated. Phenolics resulting from the condensation of separate monomers are not represented in the figure to simplify the classification
At the undergraduate level, one should be able to recognize moieties in molecules and be aware of the major phenolics molecules. At the graduate level, one should realize that to understand nature and put things together, having these molecules as part of the basic vocabulary and knowledge will undeniably broaden your knowledge and open the doors of multidisciplinarity.
4.6.3 Monomeric phenols
4.6.3.1 C6 phenols
Monomeric phenols and phenolic acids are not naturally abundant as separate molecules. However, many of them end up as moieties of more complex phenolic molecules. We decided to present several of them in more details. Before we do that, and to ease the description of phenolics, some nomenclature is useful. As stated before, nucleophilic and electrophilic additions do not occur on aromatic rings, only substitutions of H for other functional groups. But the substitution do not occur randomly. They either occur on an ortho, meta, or para locations on the aromatic ring, compared to the reference substituent (X in Figure 4.79). In reality, for what we are concerned, the reasons why subtitutions occur in either of these positions is beyond our scope and interest. However, through this section, ortho, meta, and para are sometimes used to more precisely describe molecules.

Figure 4.79: Left: Examples of monomeric phenols in C6 differing from the number and placement of the hydroxy groups on the benzene ring (non-exhaustive list). Right: illustration of the ortho, meta, or para substitution locations on aromatic rings, where X represents any radical or carbon chain
- Catechol
Catechol (1,2-Benzenediol; Figure 4.79 and 4.80) can be found in small quantities in fruits and vegetables. Its name comes from the southeast Asian acacia tree Senegalia catechu called kachu in Malay. From this tree, the catechu (latinized version of kachu), sometimes called cachou is extracted for pharmaceutical, tanning and coloring purposes. You have seen its oxidation into a reddish-brown melanoid pigment when you cut an apple or a potatoe and you leave them exposed to oxygen of the atmosphere. It is actually your cutting that allows mixing of catechol with the polyphenol oxidase (PPO) naturally present in the chloroplasts of apples, which allows the oxidation of catechol (into 1,2 benzoquinones or ortho-benzoquinones; see difference with 1,4 benzoquinone in Figure 4.79), only in the presence of oxygen though. Benzoquinones can polymerize together or bind with amino acids to form the brown color you recognize right away. This also corresponds to the phenomenon when fruits or vegetables are bruised or indented, and the process is generally referred to as enzymatic browning (Figure 4.80).
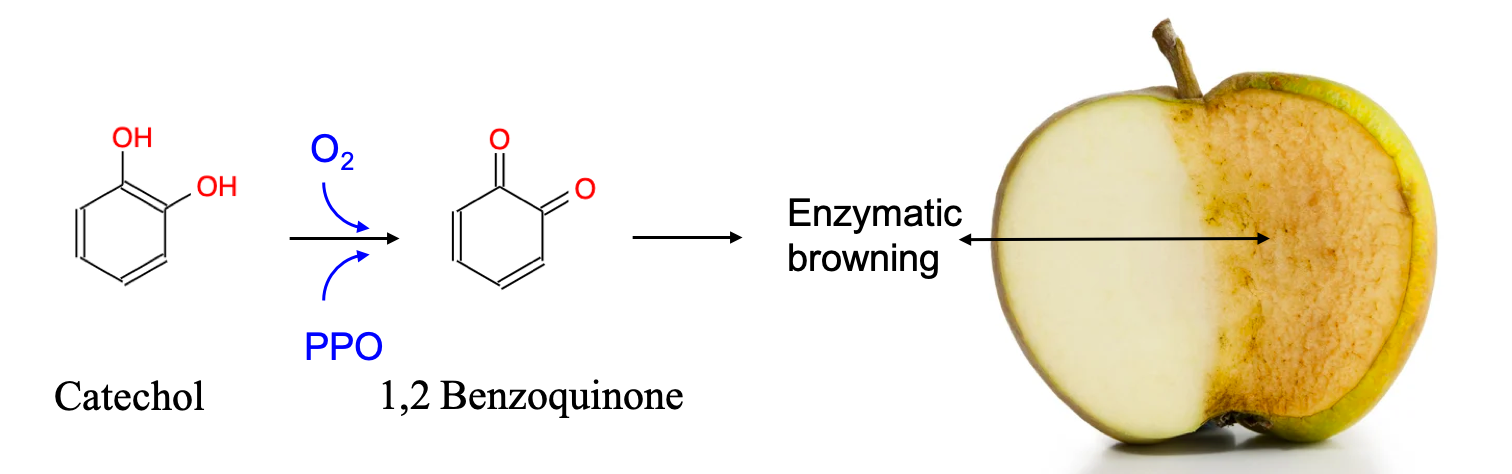
Figure 4.80: Enzymatic browning due to the oxidation of catechol into ortho-benzoquinone, reacting with itself or with amino acids to form the familiar brown color on apples or potatoes freshly cut and left in contact with oxygen
This everyday life observation is actually of utmost importance for ecological engineering: many extra-cellular enzymes exuded by microbes to catabolize organic matter for their respiration are stimulated or reversely inhibited by the presence or absence of oxygen. In fact, we shall see later that it is the phenol oxidase enzymes and the presence of oxygen that control much of the mineralization of organic matter in ecologically engineered treatment systems.
You have certainly heard about catecholamines, which serve as neurotransmitters, one of which is dopamine, or the ‘pleasure molecule’, the one your brain releases upon watching screens… Dopamine has an ethylamine group attached to a catechol moiety. Urushiols, the oil developed by the poison ivy and poison oak present on the American continent has a catechol moiety to which long aliphatic unsaturated chains are attached.
The catechol moiety is at the basis of many more complex phenolics. So it is for resorcinol, the second isomer of catechol (Benzene-1,3-diol, Figure 4.79), which does not really exist in nature as a separate entity, although it is widely used for the industrial production of phenol formaldehyde resins such as Bakelite.
- Hydroquinone and Benzoquinone
The third Benzenediol is hydroquinone. Quinone comes for quin(a) the Spanish writing of the Quechua word kina (which mean trunc or more likely bark) + -one for the two ketone functional group. In hydroquinone, the prefix hydro-, stands for hydrogen, and hydroquinone is a benzoquinone that has gained hydrogens and electrons, and it is the reduced compound of benzoquinone (Figure 4.81).
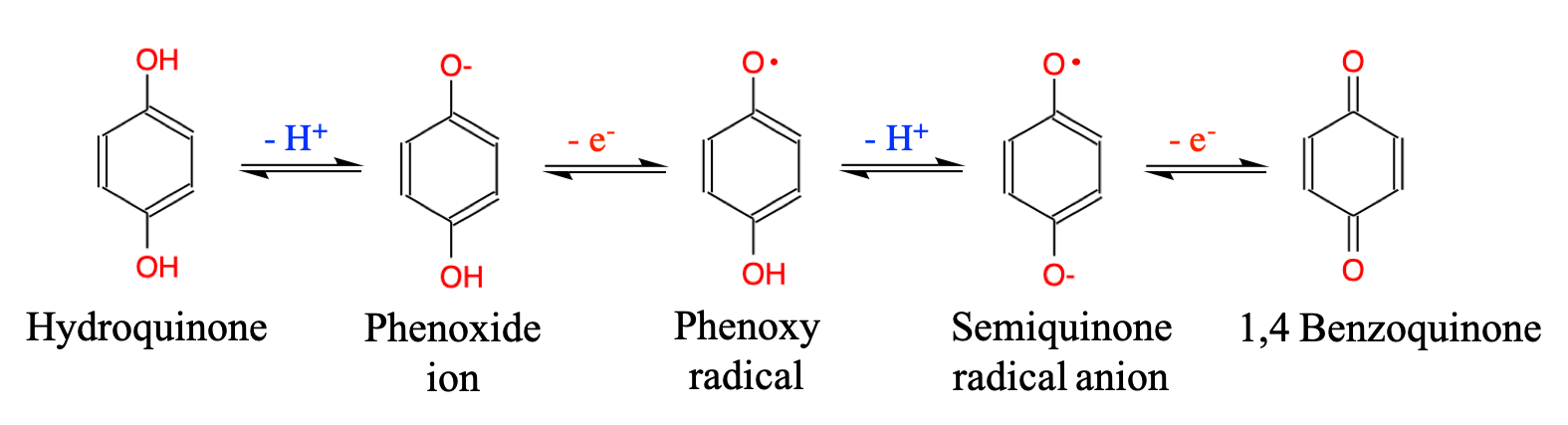
Figure 4.81: Oxidation of hydroquinone to para-benzoquinone or 1,4-benzoquinone, with intermediates, including the supereactive semiquinone radical
On a side note that is quite fascinating, nonetheless, the bombardier beetle has the ability to spew para-benzoquinone and methyl para-benzoquinone to defend itself from predators. Their defensive apparatus consists of two compartments known as the reservoir and the reaction chamber. When challenged, muscles surrounding the reservoir containing 1,4-hydroquinone and 2-methyl-1,4-hydroquinone (Figure 4.82 left) contract sending these into the reaction chamber where they mix with enzymes and hydrogen peroxides. The highly exothermic oxidation upon mixing generates so much heat that temperatures reach 100°C vaporizing water, resulting, many times per second, in an explosive discharge of a hot noxious chemical spray containing two major quinones: 1,4-benzoquinone and 2-methyl-1,4-benzoquinone [Figure 4.82 left; Attygalle et al. (2020)]
![Biosynthetic formation of hydroquinone resulting, when mixed with H~2~O~2~ in a reaction chamber, in the production of noxious gas mist (left), or high pressure directed jet stream of para-benzoquinone for the rightfully called *bombardier beetle* (right) (after [@Attygalle2020-wf] and [@Eisner1999-pm])](pictures/bombardier.png)
Figure 4.82: Biosynthetic formation of hydroquinone resulting, when mixed with H2O2 in a reaction chamber, in the production of noxious gas mist (left), or high pressure directed jet stream of para-benzoquinone for the rightfully called bombardier beetle (right) (after (Attygalle et al. 2020) and (Eisner and Aneshansley 1999))
- Phloroglucinol
From the Greek Phló(os) (φλοιός, which means bark, tree bark, fruit skin) + r(hiza) (ῥίζα, which means root) + o + glukús (γλυκύς, which means sweet) + suffix -ol because of all the hydroxy/alcohol groups. Phloroglucinol (Figure 4.79) moiety is commonly found in the ring A of flavonoids (see below). It also corresponds to the monomer of phlorotanins found in marine brown algae. You might have already encountered phloroglucinol as it is commonly used as a spasmolytic agent to treat colic, as well as spastic pain of the digestive and biliary tracts.
- Pyrogallol
Pyrogallol (Figure 4.79) is a monophenol compound with 3 hydroxy groups, two of which placed in ortho on either side of the central one. It is a toxic compound by itself. The prefix Pyro- in pyrogallol signifies ‘pure’, and the suffix -ol gives an indication that there are alcohol groups, in fact three. In reality, pyrogallol corresponds to the C6 part of the lot more common gallic acid, which is a C6-C1 monomeric phenol. The latter is found in galls, common on many trees and shrubs including oak (Quercus), mapple (Acer), or dog rose (Rosa canina; Figure 4.85).
- Guaiacol
Anisol, from which the anis aroma comes and not illustrated in this section, is a phenol which hydroxy group has been replaced by a methoxy one. Guaiacol is a bit of a mix between phenol and anisol: a methoxy group has been substituted on the ortho position (Carbon next to the -OH of phenol; Figure 4.79 and 4.83). Guaiacol was named by Unverdorben after it was found after distillation of the Guaiacum tree resin or wood creosote (Unverdorben 1829). Guaiacum trees are native to subtropical and tropical regions of the Americas and the prefix guaiac- comes from the Taíno language originally spoken in the Bahamas. The wood of guaiacum trees has among the highest density in the world (1.3) and therefore sinks in water.
Guaiacol and its derivatives have widespread presence in flora and fauna and are used as aroma components in the food and perfume industry and as local anesthetics and antiseptics in medicine. Guaiacol is responsible for the flavor of smoke in smoked and roasted foods such as bacon, fish, and coffee. Guaiacol and its diverse derivatives are well-known for their smoky, ham, vanilla-like, clove-like, medicinal odors [Figure 4.83; reviewed by Ghadiriasli et al. (2019)].
![Guaiacol and alkyl, alkenyl, and halogenated derivatives have ham, vanilla-like, clove-like, medicinal, or smoky odors. [after @Ghadiriasli2019-up]](pictures/guaiacol-odors.png)
Figure 4.83: Guaiacol and alkyl, alkenyl, and halogenated derivatives have ham, vanilla-like, clove-like, medicinal, or smoky odors. (after Ghadiriasli et al. 2019)
4.6.3.2 C6-C1 phenolics: benzoic acid and benzaldehyde derivatives
Their basic skeletons are benzoic acid or benzaldehydes (Figure 4.84) and they differ by the number and location of the hydroxy- and methoxy-substitution on the aromatic ring. Notice the appearance of the methoxy group (-O-CH3) on the benzene rings (it already appeared in guaiacol; Figure 4.83). This observation gives a chance to review some of the diversity among the C6 and C6-C1 monomeric phenols. Much of the diversity among them is associated with the nature, number, and placement of the substituents, none of which occurs by accident. For the C6 phenols, the nature of the substituents can either be -OH (hydroxy) or -OCH3 (methoxy). The same applies for the C6-C1 monomeric phenols, although additional diversity comes with the group forming the C1, which usually comes as a carboxyl (-COOH), an aldehyde (-CHO), or much less often as a methyl (-CH3).
And so what? Well, to better understand how phenolics work, it is important to realize that the Cn (n = 1 to 3, 7) aliphatic chain substituents generally tend to withdraw electrons from the aromatic ring when they have double bonds associated with an oxygen atom. Reversely, substituents like -OH and -OCH3 tend to donate electrons to the aromatic ring thanks to the lone pair of electrons on the oxygen atom bonded to the ring, creating a resonnance effect (see more details below). Again, the Cn chains tend to withdraw electrons and are referred to as electron withdrawing groups - EWG while the hydroxy and methoxy groups are referred to as electron donating groups - EDG. For all the details on how this works, you may read section 17.5.1 in the glossary.
All in all, phenolics are generally built such that the effect of the EWG and EDG neutralize each other to a large extent. The placement of the -OH and -OCH3 on ortho, meta, para positions (Figure 4.79) has further implication on how the π electrons are delocalized, although this is still the topic of active research. The consequences for us are that light may be absorbed differently yielding variable optical properties among phenolics (e.g., flower pigments, light absorbance of water) and of organic matter in general. In ecological engineering and in environmental sciences in general, this is the basis of why we measure absorbance of light in water as it can give quantitative and qualitative information on dissolved organic matter.
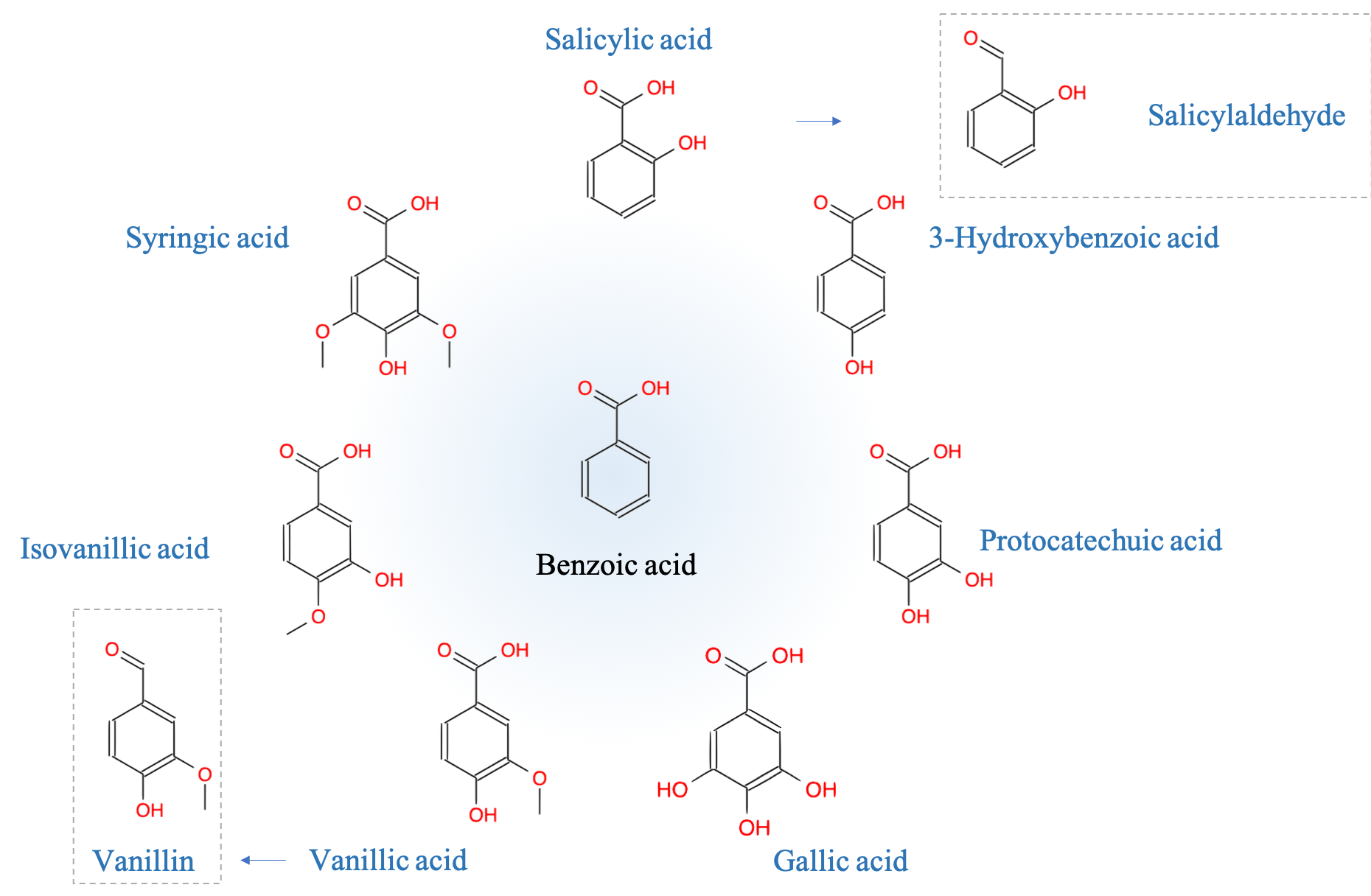
Figure 4.84: Examples of monomeric phenols in C6-C1 configurations differing from the number and placement of hydroxy and methoxy groups on the benzene ring (non-exhaustive list)
- Salicylic acid:
Of note is salicylic acid, not quite as famous as acetyl salicylic or commonly called aspirin, where an acetyl group (-OOC-CH3) makes an ester bond with the hydroxy group on the benzene ring. The word salicylic comes from the Latin Salix, name of the willow tree, in the bark of which this acid was first discovered. Salicylic acid is also found in Filipendula ulmaria (meadowsweet in English, a common perennial herbaceous plant of Europe and Western Asia) also named Spirea ulmaria, and from which the word aspirin is derived with the prefix a- standing for acetyl.
- Vanillin:
Vanillin, the primary component of the extract of the vanilla bean, is the benzaldehyde version of vanillic acid and counts among the most used benzaldehydes.
- Gallic acid
Gallic acid (Figure 4.84), with pyrogallol (Figure 4.79), is a toxic compound. Gallic acid is the central moiety of ellagitannins and gallotannins (details below), which are particularly concentrated in plant galls, hence their names. Galls are common on many trees and bushes such as oaks (Quercus sp.), rosebush or dog rose (Rosa canina), or maples (Acer sp.) (Figure 4.85). These are reactions of the plants to the biting of specialized hymenoptera insects of the Cynipidae family, in which they lay their eggs. The latter is found in galls, common on many trees and shrubs including oak (Quercus), mapple (Acer), or dog rose (Rosa canina; Figure 4.85). Galls were commonly used to tan leather. This tanning ability of tannins is described in more details later.
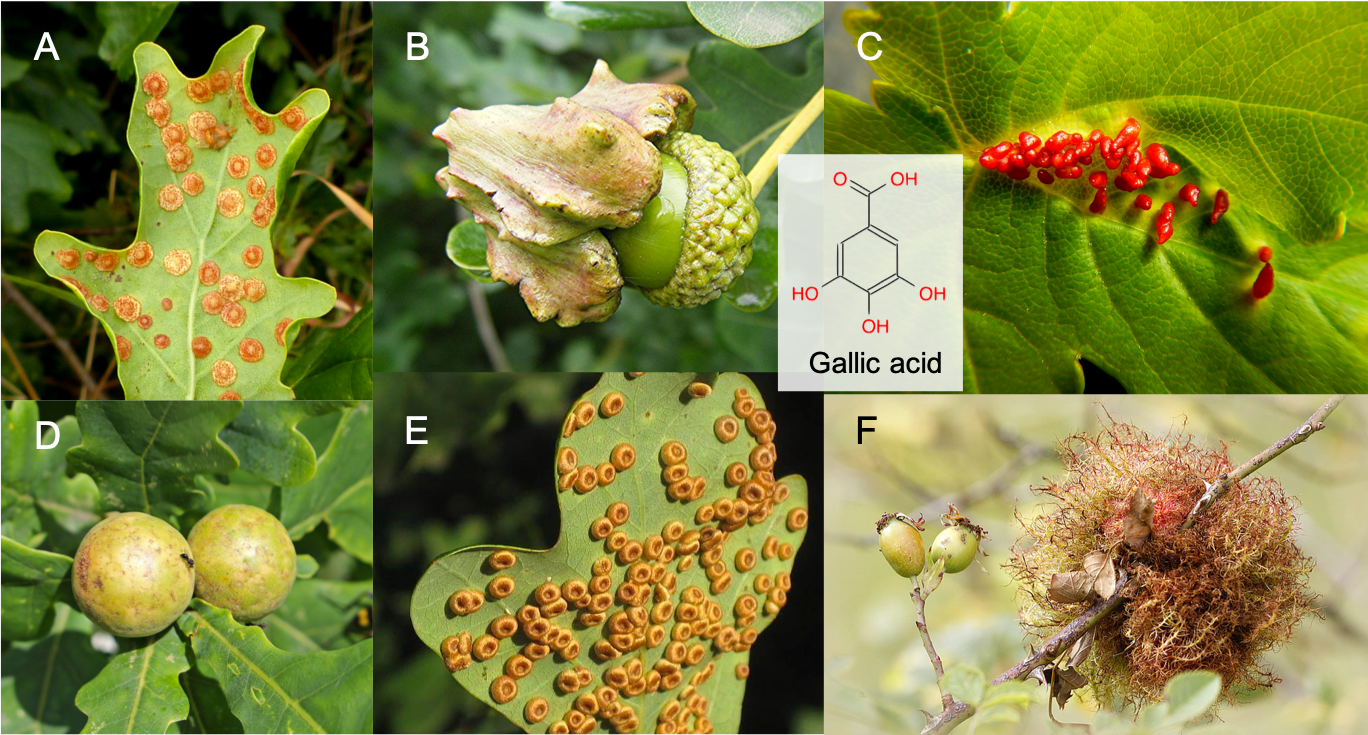
Figure 4.85: Galls are commonly found on oak (A, B, D, E), mapple (C), or dog rose (F). They are reactions for these plants to small hymenoptera insects that use them for the development of their larvae. Galls were widely used for their tanning ability as up to 70% of their dry weight is made of gallo-tannins
- Syringic acid:
Syringic acid is present in many fruits, including olives, dates, pumpkins, the acai palm, honey and certain spices. It is found in higher concentrations in blue berries such as blueberries or red grapes, and therefore in red wine. It is notably formed by the decomposition of oenin, an anthocyanin that dyes the grapes and red wine. It is also present in vinegar (Wikipedia contributors, n.d.a). Its name comes from Syringa, the latin name of the common Lilac, as it derives from the syringine glucoside first found in bark of the common lilac.
- Protocatechuic acid:
Protocatechuic acid (PCA) is antioxidant and anti-inflammatory and is a major metabolite of antioxidant polyphenols found in green tea. It is also one of the main metabolites of complex polyphenols, such as anthocyanins and proanthocyanins. Protocatechuic acid may act as antioxidant, anti-inflammatory, neuroprotective, antitumor, antibacterial, antidiabetic, and antiapoptotic agents (Song et al. 2020; Zhang et al. 2021).
4.6.3.3 C6-C2 phenolics: Phenylethanoids and derivatives
Three main groups of phenylethanoids have been identified: phenylethanoic acids, acetophenones, and phenylethyl alcohol derivatives. Figure 4.86 illustrates the basic skeletons of these phenylethanoids. Actual molecules differ from additions of hydroxy groups (-OH) and methoxy groups (-OCH3) on the benzene ring, on carbons 3, 4, or on both. The carbon on which the Cn group is linked is referred to as carbon number 1 (Figure 4.86).
Phenylacetic acid has a honey-like odor and serves as a plant hormone in fruits. Acetophenones are found in many foods including apple, cheese, apricot, banana, beef, and cauliflower (Wikipedia contributors 2021b). Tyrosol and hydrotyrosol are phenylethyl alcohols with hydroxy groups, respectively, on carbon 4 and carbons 3 & 4. They are found in olive oil and have been shown to have potent antioxydant capabilities. Hydroxytyrosol is involved in many other molecules such as the oleuropein, the molecule that gives bitterness to raw olives and that must be removed for olives to become edible.

Figure 4.86: Basic skeletons of monomeric C6-C2 phenols referred to as phenylethanoids. These are often associated with fragrance of fruits and vegetables and have antioxydant properties
4.6.3.4 Conjugated bonds as a basic structural pattern
Time to pause. Let us be frank, the litany of phenolics types and names can become quickly overwhelming, unless you are a hardcore biochemist (but you would not be reading this book) or a naturalist with an unquenchable desire to discover nature’s diversity. In reality, among this incredible diversity of phenolics molecules, and we have only started this exploration, one has to wonder why these molecules are arranged the way they are, and what are the common themes behind this diversity. We have already addressed the part that concerns the nature, number and location of the substituents earlier. But as the size of these molecules increases, several questions arise: why are these molecules so stable in their structure, why do they have anti-oxidant properties (and what does it mean?), and why do they have pesticide properties? The basic and simple answer to these questions is: conjugated double bonds create very stable electronic resonance that explain a lot of their properties.
Recall that resonance describes the delocalization of electrons within molecules and the more resonance structures the more stable molecules tend to be. In the section introducing aromatic and phenyl functional groups, we saw that one of the reasons for the stability of the benzene ring was what we refer to as conjugated double bonds. What does this mean again? It means that, for example in a C7 aliphatic chain (Figure 4.87), there would be 3 double bonds alternating with 3 simple bonds between the carbon atoms. Their respective locations are illustrated in the top of Figure 4.87 and both can co-exist. These are called resonance structures as they both describe the possible locations of the electrons. The same thing is true for the benzene ring (middle equation of Figure 4.87, left and middle structures), where the location of the double bonds can theoretically alternate. Experimental measurements of the C-C bond lengths in benzene suggests, however, that they are all the same, which would not be the case for stable single and double bonds. So in reality, the π electrons of the double bonds of benzene are delocalized among all carbon atoms. Molecular orbital theory also suggests that the electrons are delocalized onto all atoms of carbon in benzene.
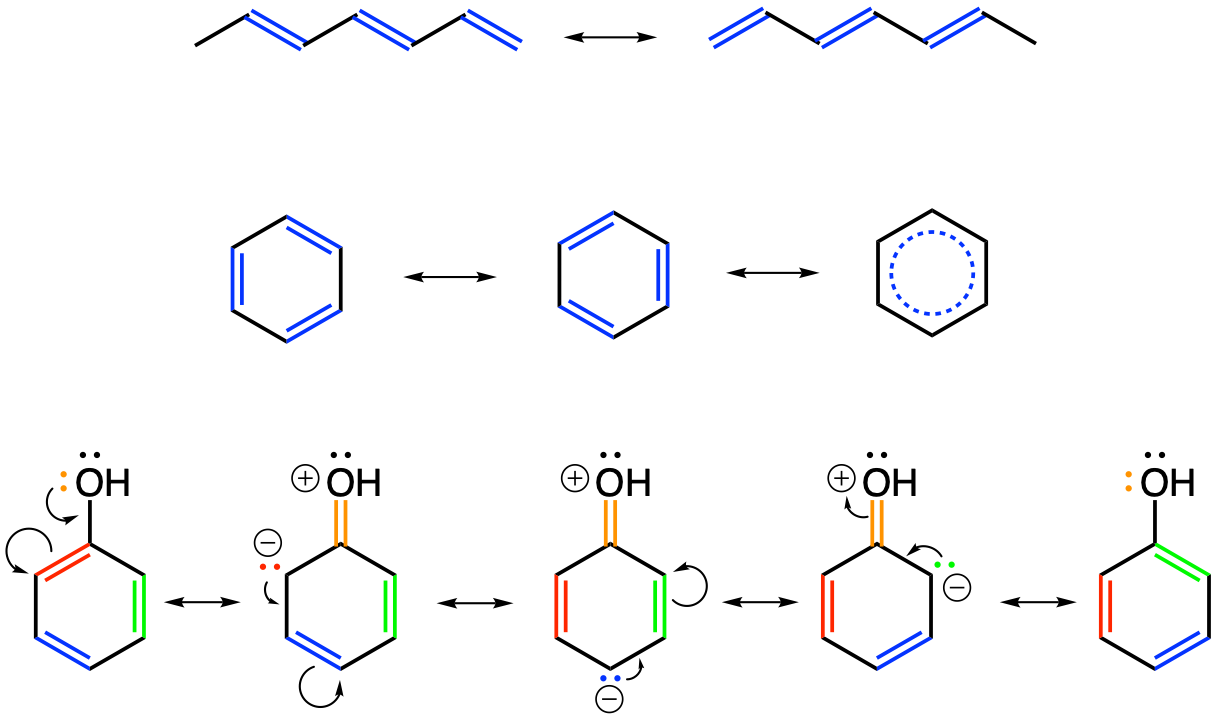
Figure 4.87: Illustration of conjugated double bonds in a hypothetical C7 aliphatic chain (top; hepta-2,4,6-triene and hepta-1,3,5-triene): double and single bonds alternate, and their exact respective location suggests that both forms co-exist. The same thing is true for the benzene ring (bottom) where the location of the double bonds can be in the form to the left or middle. Molecular orbital theory suggests that in reality the electrons are delocolized onto all atoms of conjugated bonds (bottom right): this is called resonance
Because, either resonance structures of benzene do not represent where the electrons are located, aromatic rings are often represented with a dotted (sometimes solid) circle in the middle of the C6 cyclic chain representing the 6 π delocalized electrons and this representation is referred to as the resonance hybrid structure (right structure of the middle equation in Figure 4.87). The electronic delocalization lowers the electron energy level and is called resonance stabilization. This makes for exceptional thermodynamic and chemical stability of the benzene rings, and of phenolics in general. The bottom equation of Figure 4.87 illustrates the five resonance structures of phenol.
While there is free rotation around σ bonds, the combined σ and π double bond is rigid and prevents rotation of aliphatic chains around the double bond. As a result, molecules with conjugated double bonds, such as for the C7 triene, benzene, or phenol in Figure 4.87 are all planar. In fact, this is both a prerequisite and a consequence for resonance to occur. Actually, this property has some major impacts on phenolics stability and instability, and their reactivity with the environment.
In summary,
- the conjugated double bonds allow for resonance stabilization of the phenolics molecules
- the resonance stabilization of the aromatic rings is exceptional among alkenes
Double bonds tend to be rather fragile and break because the π electrons are more loosely attached to the atoms. In the case of phenolics, the aromatic rings do not break but rather undergo substitution reactions. In other words, the hydrogens on the C6 ring get substituted by hydroxy or methoxy groups (more rarely by other groups such as methyl), and the aromatic ring retains its resonance stability. This is the core of C6 phenols. But we already know that phenolics molecules have hydrocarbon chains attached to the aromatic rings (Figure 4.78). The secret to the structure and function of phenolics is maintaining conjugated double bonds and electronic resonance in their basic structure, even with the addition of carbon and oxygen atoms. Figure 4.88 summarizes how conjugated double bonds are the common theme and rule among phenolics
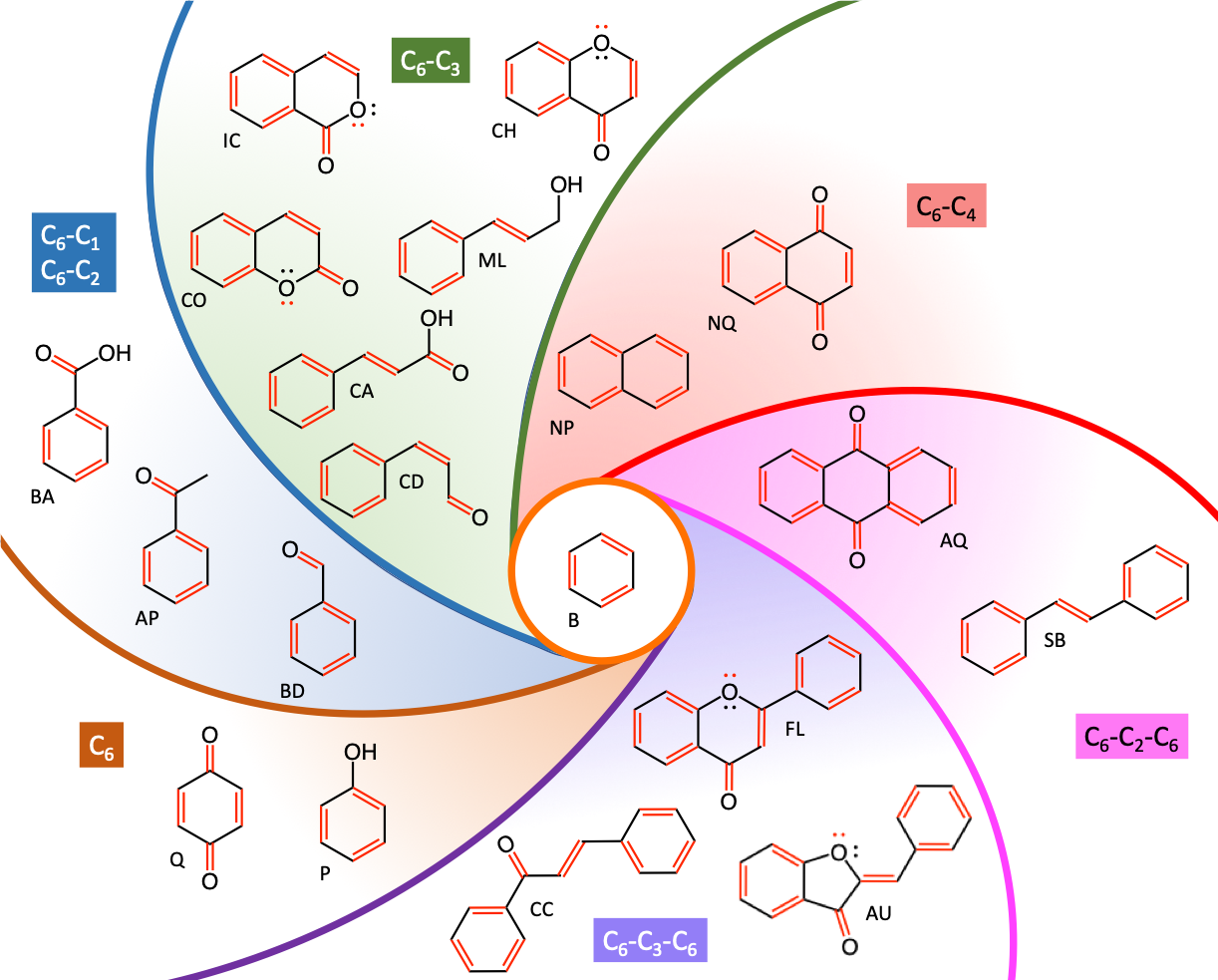
Figure 4.88: The secret to the structure and function of phenolics: maintaining conjugated double bonds and electronic resonance among atoms of C6, C6-Cn, and C6-Cn-C6 monomeric phenols. All double bonds have been illustrated in red, as well as the lone pair of electrons on the oxygen atoms, which participate in the electronic resonance of the phenolics compounds. For clarity purposes, only the phenolic skeleton have been illustrated. (B-Benzene; P-Phenol; Q-Quinone; BD-Benzaldehyde; AP-AcetoPhenone; BA-Benzoic Acid; CA-Coumaric Acid; CD-Coumaric Aldehyde; CO-Coumarin; IC-Iso-Coumarin; ML-MonoLignol; CH-Chromone; NP-Naphtalene; NQ-Naphtoquinone; AQ-Anthraquinone; SB-Stilbene; AU-Aurones; FL-Flavonoid; CC-Chalcone)
Just imagine, one is given the task to build from the benzene ring complex molecules that would maintain resonance even with the addition of carbon and oxygen atoms. Well, all the C6 molecules (Figure 4.79) varying by the differences in the type and number of substituents would work. The quinone molecule where the double bonds of the carbonyl groups at opposite ends of the aromatic ring would also provide conjugated double bonds (Q in Figure 4.88)
Now, let us try to expand the phenolics molecule with one or two carbon atoms while still maintaining the conjugated bonds. The thing one could do is add an aldehyde (-CHO) to form benzaldehydes (BD in Figure 4.88), or a carboxyl group (-COOH) to form benzoic acids (BA in Figure 4.88). Adding an acetyl to form an acetophenone (AP in Figure 4.88) would also work. In all cases, the double bond of the carbonyl group (-C=O) can enter in resonance with the electrons of the aromatic ring, which suggests that the final molecules would be planar. Experience shows that in fact this is the case, although the space taken by the aldehyde, carboxyl, and acetyl groups would suggest otherwise, with functional groups at an angle with the aromatic ring (reviewed by Badhani, Sharma, and Kakkar 2015). An addition of an ethene group would also work, but there are no report in the literature that mention these, possibly because the double bond at the end of an aliphatic chain is fragile and susceptible to breaking.
Next comes the addition of three carbon atoms. The obvious solution for that is to add a propene tail, where there would be a double bond that would be conjugated with the ones on the aromatic ring. And indeed, such propene tails exist in nature and are referred to as propanoids, i.e., pseudopropanes. Having the propanoid end carbon be part of an aldehyde (-CHO) or a carboxyl group (-COOH), adds a double bond and provides further stability to the C6-C3 molecules. And indeed, among the C6-C3 molecules, we shall see that there are coumaric aldehydes (CD in Figure 4.88) and coumaric acids (CA in Figure 4.88). An alcohol group at the end of the propanoid chain does not provide a full π electron resonance, but one of the lone pairs of electrons on the alcohol group at the end of the chain can participate to some extent to resonance. Monolignols (ML in Figure 4.88), the monomers of lignins, are built according to this scheme.
Now, if one were to bend the propanoid tail of coumaric acid, such that the alcohol group would bend toward the aromatic ring, then after condensation (and removal of two hydrogen atoms), a second ring could form. Coumarin molecules (CO in Figure 4.88) are built on this scheme. Actually, in this configuration, double bonds are not entirely conjugated because of the oxygen atom closing the ring. However, one of the lone pairs of electrons on the oxygen atom that closes the second ring can participate to some extent to the resonance of the molecule, creating a pseudo-resonance inside the molecule. Isocoumarins and chromones (IC and CH in Figure 4.88) are isomers of coumarins and have the same pseudo-resonance pattern.
What about adding four carbon atoms? The easiest answer is to add a second fully aromatic ring resulting in naphtalene (NP in Figure 4.88). The two double bonds added are conjugated with the orginal aromatic ring. A quinone ring with double bonds provide a total of three double conjugated double bonds resulting in napthtoquinones (NQ in Figure 4.88), which are very potent phenolic pesticides.
Apparently, the addition of 5 to 7 carbon is unstable as the next way to add conjugated double bond chosen by nature, is to add another aromatic ring with some intermediate structure where resonance would be maintained. The solutions nature has kept are anthroquinone where two aromatic ring are fused with a quinone structure (AQ in Figure 4.88) and by a propene chain such as in stilbenes (SB in Figure 4.88).
Finally, one could add yet another carbon (9 in addition to the initial benzene ring), one solution nature has found to keep at least a pseudoresonance is to add an entire aromatic ring to a chromone molecule (FL in Figure 4.88), and this corresponds to the flavonoids, the most studied and numerous group of polyphenols. Another solution is to leave the middle ring open: chalcones are built upon this scheme.
In summary, the basic structure of monomeric phenolics is very logical as it involves conjugated double bonds to allow electronic resonance, although sometimes only a pseudoresonance is reached. In reality, although the principles of conjugated double bonds and electronic resonance are the rules or the common theme among the structures of phenolics, there are lots of exceptions and variations around that theme. Given this grid of analysis, we can resume our discovery of the next group of monomeric phenols: the phenylpropanoids or the C6-C3 molecules.
4.6.3.5 C6-C3 phenolics: Phenylpropanoids and derivatives
With three carbon chains substituted on the aromatic phenol ring, the number of possible molecules increases considerably. It would be futile to describe them all here. The general rule for resonance described above generally holds, but has quite a few exceptions as well. We chose cinnamic acid as the basic model of a generic phenylpropanoid (Figure 4.89). The suffix-oid stands for pseudo, so in the word propanoid, this suggests that the basic propane skeleton has undergone modifications. And to simplify everything, the term propanoid is used and refers to all the C3 chains that are modified. In fact, in cinnamic acid (Figure 4.89), the propanoid tail is a propenoic acid, the simplest unsaturated caboxylic acid. Notice that in the term phenylpropanoids, the aromatic ring appears as a group attached to the propanoid chain. This is just a naming convention that does not have chemical meaning though.
Phenylpropanoids occur universally in plants and are also the precursors of many other classes of plant phenolics, including flavonoids, stilbenoids, and xanthones (Lattanzio 2013).
Cinnamic acid:
As its name indicates, cinnamic acid is especially found in cinnamon oil and Storax
eugenol, isoeugenol
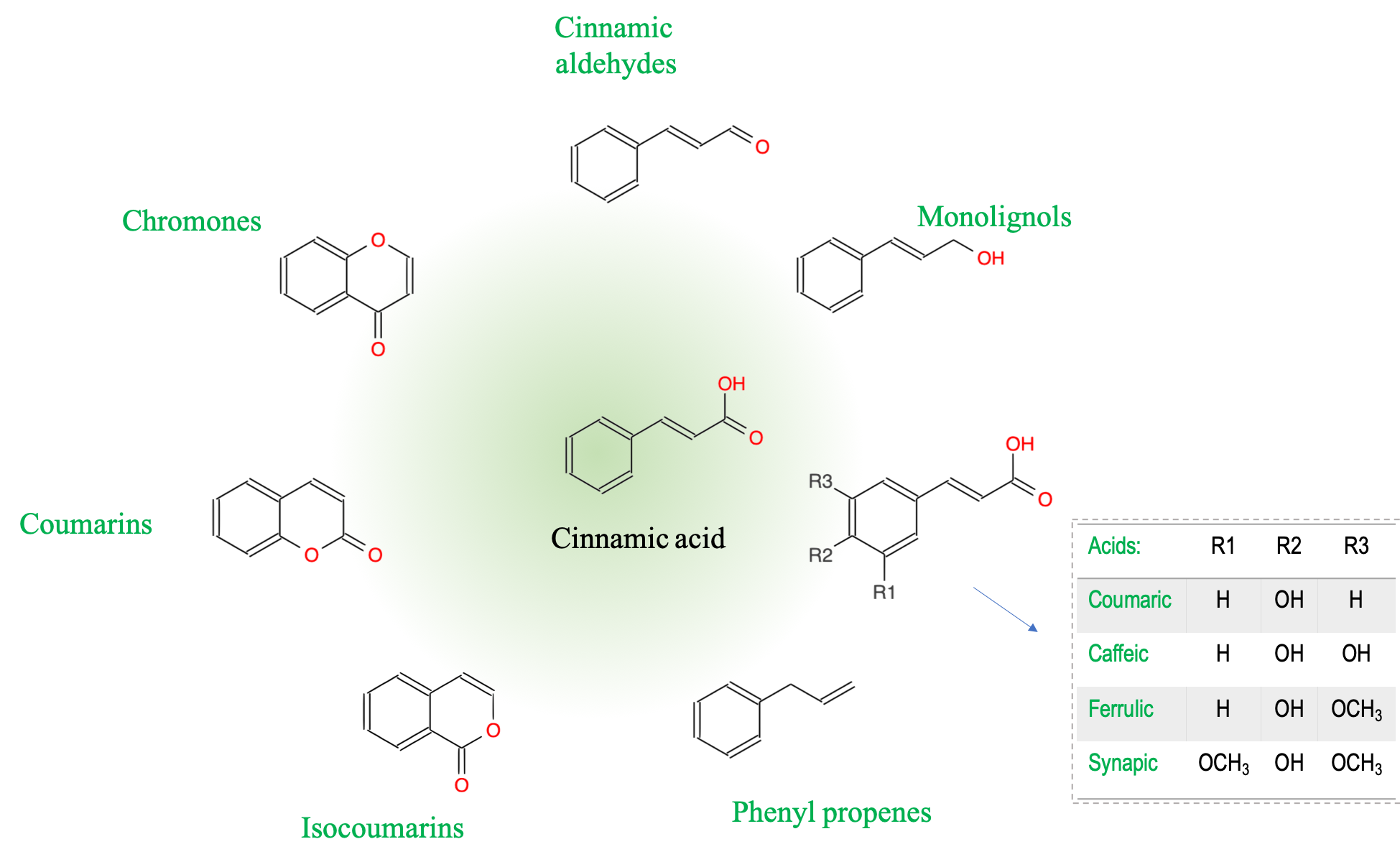
Figure 4.89: Basic skeletons of monomeric C6-C3 phenols referred to as phenylpropanoids
4.6.3.5.1 Anthraquinones
Among the anthraquinones, it is fascinating to see the importance of two of them in history! Alizarin and purpurin are two anthraquinones that are extracted from the madder plant (Rubia tinctorum L.) originating from the middle east (Figure 4.90). The word Alizarin is derived from the French Alizarine, itself derived from the Greek αλιζάρι (alizári, “madder”), itself derived from Ottoman Turkish آلاجهری name of the plant. The word purpurin exists in English and a synonymous is crimson.
Well, the madder plant root (garance in French, from the old French warance meaning scarlet) can be ground to extract the scarlet pigments that they contain, i.e., alizarin and purpurin. This was known since the Antiquity in the middle east and Egypt (the Egyptian flag still has the alizarin red in it). But is was not until the mid 1700s that a Persian-born Armenian named Hovhannès Althounian (later naturalized as Jean Althen) brought it to France from where its pigment industry would blossom. He was made a slave by the Ottoman Turks after the latter massacred his entire family, and worked in the madder and cotton plantations for 15 years until he escaped with some precious madder seeds. By the 1820s, madder plantations were all over southern France and the root extract called garancine was used all over the world to dye fabric in red. The color of the fabric was so vivid and appreciated that even the French and British armies use the red uniform throughout the 1800s (Figure 4.90)! This might also have had to do with better vision among the smoke produced by black powder guns of the time. Purpurin, the oxydated version of alizarin was found not to be as stable as a dye though.
Figure 4.90: The red alizarin and purpurin anthraquinones have been extracted from the madder plant roots (Rubia tinctorum L.) since Antiquity and used worldwide to dye fabric in red since the 1820s. The French soldier uniform pants were dyed in ‘madder red’ (‘rouge garance’ in French) for nearly a century until world war I. The fifer player (Le joueur de fifre in French) is a famous painting from Édouard Manet that shows well red rendered by alizarin
In 1869, alizarin became the first natural pigment to be produced synthetically. German chemists Carl Graebe and Carl Liebermann, employees at BASF, found a way to obtain it from anthracene. A day later, the English chemist William Henry Perkin discovered the same synthesis, independently of the German team. The BASF group filed the patent one day before Perkin and started marketing alizarin in 1871 (Wikipedia contributors, n.d.b). The consequences were that all the madder plantations went out of business within the next ten years. The French army decided to continue support madder growers and its industry for years after that, and this is how the French soldiers appeared against the Prussians in the 1870 Franco-Prussian war. The garance trousers became the symbol of a defeat, but also of the revenge. So much so that while all other armies had changed their uniform for more discrete colors at the turn of the century, the French army soldiers showed up in red trousers and were great targets for the Germans at the onset of the first world war in 1914…! All that because of this alizarin anthraquinone!
Phlorotannins are polymers of 2 to 6 phloroglucinol units (Amsler and Fairhead 2005) attached via ether and covalent bonds (Figure 4.91). Phlorotannins provide protection against the UV light, appear to have antiherbovory effects, in part because of detrimental effects on herbivore digestion as phlorotannins form complexes with digestive proteins and other macromolecules, and probably have antifouling effect although this is disputed (Amsler and Fairhead 2005; Hurd et al. 2014).


Figure 4.91: Phlorofucofuroeckol (left) and Tetraphlorethol (right) are polymers of respectively 5 and 4 phloroglucinol monomers bonded together by ether and covalent bonds. These are only two among 150 phlorotannins listed which provide UV protection and tend to deter herbivores (grey = C atom, red = oxygen atome, white = hydrogen atom)
4.6.4 Lignins
Lignin (from the latin lignum, meaning wood) is, after cellulose, the second most abundant terrestrial biopolymer, accounting for approximately 30% of the organic carbon in the biosphere. The ability to synthesize lignin has been essential in the evolutionary adaptation of plants from an aquatic environment to land. Lignin is crucial for structural integrity of the cell wall and stiffness and strength of the stem. In addition, lignin waterproofs the cell wall, enabling transport of water and solutes through the vascular system, and plays a role in protecting plants against pathogens (Boerjan, Ralph, and Baucher 2003).
It is thought that it is the multiple aromatic rings of the phenylpropanoids that provide the stiffness of lignin, hence of wood.
](pictures/monolignols.png)
Figure 4.92: Three common monolignols, monomers for the lignin molecules: paracoumaryl alcohol (1), coniferyl alcohol (2) and sinapyl alcohol (3) By Yikrazuul - Own work, Public Domain
Lignins are polymers of a lot more complex monomers than the monosaccharides presented earlier. The monomers of lignin are called monolignols. Nothing to be scared of, because there is no expectation for the reader to know them! Technically, the lignin monomers are generally referred to as phenylpropanoids (which means that there is a phenol radical attached to a propane like C3 structure). The suffix -oid means pseudo), and technically derived from hydroxycinnamyl alcohol differing in their degree of methoxyation, p-coumaryl, coniferyl, and sinapyl alcohols (Figure 4.92).
![Illustration of the diversity of monomers and polymer units present in lignins [@Boerjan2003-sd]](pictures/lignins.jpeg)
Figure 4.93: Illustration of the diversity of monomers and polymer units present in lignins (Boerjan, Ralph, and Baucher 2003)
When introduced in the lignin polymer the corresponding monolignols are named guaiacyl (G), sinapyl (S), and hydroxy-coumaroyl (H) units, respectively (Figure 4.93). The G, S, and H abbreviation letters are often used in the lignin literature. For example, the composition of lignin varies between plant species and tissues. In general, lignins from gymnosperms and related species (called softwood in English) are rich in G units and contains low amounts of H units, whereas lignins of angiosperm dicotyledons (flowing plants with reticulate or network-like leaf veins) are mainly composed of G and S units (corresponding to hardwood in English). For references only and to have some awareness of the diversity of the monomers and polymer units, Figure 4.93 has been added above. An example of a possible lignin structure is illustrated in Figure 4.94. It shows the great complexity of this second most important molecule on earth after cellulose.
](pictures/Lignin-structure.png)
Figure 4.94: An example of a possible lignin structure. The portion shown here has 28 monomers (mostly coniferyl alcohol), 278 carbon atoms, 407 hydrogen atoms, and 94 oxygen atoms. Karol Głąbpl.wiki
On an interesting note, it has recently been shown that polymerization of the monolignols is not random, but that monolignols are first assembled into lignol dimers (two monolignols), referred to as lignans. Lignans are thus dehydrodimers of monolignols (Davin et al. 1997; reviewed in Wang et al. 2013). There seems to be a plethora of lignans in nature, but exploring the literature on these reveals that some lignans, after ingestion by mamals may have anti-cancer properties! For the record and in case you are fascinated by how things are connected, some of the names and structures of these lignans are rather indicative of where they have been found or associated. For example in Figure 4.95, you can see that one of them is called pinoresinol, suggesting links with pine and resin. Another one is called lariciresinol. Larix is the genus name of the larches tree in English. Another one secoisolariciresinol, the prefix secoi-, likely having to do with sequoia, and so on. Podophyllotoxin at the left bottom is found in the toxic American mandrake, or ground lemon plant, but also on some flax seeds, and seems to be an interesting anti-oxidant for colon cancer (Fuss 2003).
![Hypothetical biosynthetic pathway leading from coniferylalcohol to podophyllotoxin showing a variety of lignans or lignol dimers used in the biosynthesis of lignin, but also having antioxidant properties beneficial for the health of mammals [@Fuss2003-ad]](pictures/Lignans.png)
Figure 4.95: Hypothetical biosynthetic pathway leading from coniferylalcohol to podophyllotoxin showing a variety of lignans or lignol dimers used in the biosynthesis of lignin, but also having antioxidant properties beneficial for the health of mammals (Fuss 2003)
Learning outcomes
at the end of this section on phenolics, you should be able to:
Lignins
- Know that lignins are the second most abundant organic polymers on earth
- Recognize that lignins provide stiffness to cell walls and allowed the emergence out of water of terrestrial vegetation to compensate for the lack of support in a gaseous milieu
- Know that lignins are polymers of monolignols and that the latter are phenylpropanoids